多处理器调度完全攻略
迄今为止,我们主要集中讨论单处理器系统的 CPU 调度问题。如果有多个 CPU,则负载分配成为可能,但是调度问题就相应地更为复杂。许多可能的方法都已试过,但与单处理器调度一样,没有最好的解决方案。
第二种方法是使用对称多处理(SMP),即每个处理器自我调度。所有进程可能处于一个共同的就绪队列中,或每个处理器都有它自己的私有就绪进程队列。不管如何,调度这样进行:每个处理器的调度程序都检查共同就绪队列,以便选择执行一个进程。如果多个处理器试图访问和更新一个共同的数据结构,那么每个处理器必须仔细编程,必须确保两个处理器不会选择同一进程,而且进程不会从队列中丢失。
几乎所有现代操作系统,包括 Windows、Linux 和 Mac OSX,都支持 SMP。本节余下部分讨论有关 SMP 系统的多个问题。
现在考虑一下,如果进程移到其他处理器上则会发生什么。第一个处理器缓存的内容应设为无效,第二个处理器缓存应重新填充。由于缓存的无效或重新填充的代价高,大多数 SMP 系统试图避免将进程从一个处理器移到另一个处理器,而是试图让一个进程运行在同一个处理器上。这称为处理器亲和性,即一个进程对它运行的处理器具有亲和性。
处理器的亲和性具有多种形式。当一个操作系统试图保持进程运行在同一处理器上时(但不保证它会这么做),这种情况称为软亲和性。这里,操作系统试图保持一个进程在某个处理器上,但是这个进程也可迁移到其他处理器。相反,有的系统提供系统调用以便支持硬亲和性,从而允许某个进程运行在某个处理器子集上。
许多系统提供软的和硬的亲和性。例如,Linux 实现软亲和性,但是它也提供系统调用 sched_setaffinity() 以支持硬亲和性。
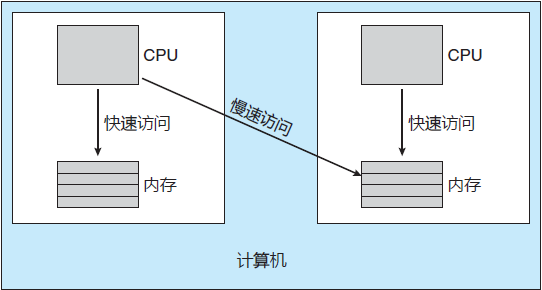
图 1 NUMA 与 CPU 调度
系统的内存架构可以影响处理器的亲和性。图 1 为采用非统一内存访问的一种架构,其中一个 CPU 访问内存的某些部分会比其他部分更快。通常情况下,这类系统包括组合 CPU 和内存的板卡。每个板的 CPU 访问本板内存快于访问其他板的内存。
如果操作系统的 CPU 调度和内存分配算法一起工作,那么当一个进程分配到一个特定的亲和处理器时,它应分配到同板上的内存。这个例子还说明操作系统通常不按教科书描述的那样清楚地定义与实现。实际上,操作系统的各个部分的“实线”通常应是“虚线”,因为有些算法创建连接以便优化性能和可靠性。
负载平衡设法将负载平均分配到 SMP 系统的所有处理器。需要注意的是,对于有些系统(它们的处理器具有私有的可执行进程的队列),负载平衡是必需的;而对于具有公共队列的系统,负载平衡通常没有必要,因为一旦处理器空闲,它立刻从公共队列中取走一个可执行进程。同时,要注意对于大多数支持SMP的现代操作系统,每个处理器都有一个可执行进程的私有队列。
负载平衡通常有两种方法:推迁移和拉迁移:
推迁移和拉迁移不必相互排斥,事实上,在负载平衡系统中它们常被并行实现。例如,Linux 调度程序和用于 FreeBSD 系统的 ULE 调度程序实现了这两种技术。
有趣的是,负载平衡往往会抵消处理器亲和性的好处。也就是说,保持一个进程运行在同一处理器上的好处是进程可以利用它在该处理器缓存内的数据。无论是从一个处理器向另一处理器推或拉进程,都会失去这个好处。
与通常的系统工程情况一样,关于何种方式是最好的,没有绝对规则。因此,在某些系统中,空闲的处理器总是会从非空闲的处理器中拉进程;而在其他系统中,只有当不平衡达到一定程度后才会移动进程。
采用多核处理器的 SMP 系统与采用单核处理器的 SMP 系统相比,速度更快,功耗更低。多核处理器的调度问题可能更为复杂。下面我们来分析一下原因。
研究人员发现,当一个处理器访问内存时,它花费大量时间等待所需数据。这种情况称为内存停顿,它的发生原因多种多样,如高速缓存未命中(访问数据不在高速缓冲里)。图 2 显示了内存停顿。
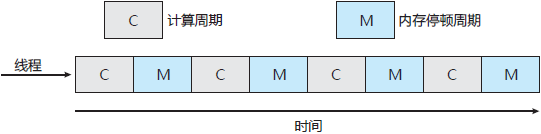
图 2 内存停顿
在这种情况下,处理器可能花费高达 50% 的时间等待内存数据变得可用。为了弥补这种情况,许多最近的硬件设计都采用了多线程的处理器核,即每个核会分配到两个(或多个)硬件线程。这样,如果一个线程停顿而等待内存,该核可以切换到另一个线程。图 3 显示了一个双线程的处理器核,这里线程 0 和线程 1 的执行是交错的。
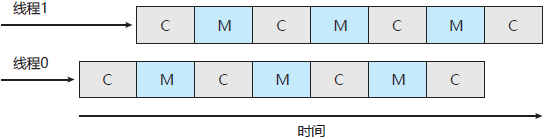
图 3 多线程多核系统
从操作系统的角度来看,每一个硬件线程似乎作为一个逻辑处理器,以便运行软件线程。因此,在双线程双核系统中,操作系统会有 4 个逻辑处理器。UltraSPARC T3 CPU 具有 16 个处理器核,而每个核有 8 个硬件线程,从操作系统的角度,就有 128 个逻辑处理器。
一般来说,处理器核的多线程有两种方法:粗粒度和细粒度的多线程。
对于粗粒度的多线程,线程一直在处理器上执行,直到一个长延迟事件(如内存停顿)发生。由于长延迟事件造成的延迟,处理器应切换到另一个线程来开始执行。然而,线程之间的切换成本是高的,因为在另一个线程可以在处理器核上开始执行之前,应刷新指令流水线。一旦这个新的线程开始执行,它会开始用指令来填充流水线。
细粒度(或交错)的多线程在更细的粒度级别上(通常在指令周期的边界上)切换线程。而且,细粒度系统的架构设计有线程切换的逻辑。因此,线程之间的切换成本很小。
注意,一个多线程多核处理器实际需要两个不同级别的调度。一个级别的调度决策由操作系统做出,用于选择哪个软件线程运行在哪个硬件线程(逻辑处理器)。对于这个级别的调度,操作系统可以选择任何调度算法。
另一个级别的调度指定每个核如何决定运行哪个硬件线程。在这种情况下,有多种策略可以采用。前面提到的 UltraSparc T3 采用一个简单的轮转算法,安排 8 个硬件线程到每个核。
再比如,Intel Itanium 为双核处理器,而且每个核有两个硬件线程。每个硬件线程有一个动态的紧迫值,它的取值范围为 0〜7,用 0 表示最低的紧迫性,而 7 表示最高的。Itanium 有 5 个不同的事件,用于触发线程切换。当这些事件发生时,线程切换逻辑会比较两个线程的紧迫性,并选择紧迫性较高的线程在处理器核上执行。
多处理器调度的方法
对于多处理器系统,CPU 调度的一种方法是让一个处理器(主服务器)处理所有调度决定、I/O 处理以及其他系统活动,其他的处理器只执行用户代码。这种非对称多处理很简单,因为只有一个处理器访问系统数据结构,减少了数据共享的需要。第二种方法是使用对称多处理(SMP),即每个处理器自我调度。所有进程可能处于一个共同的就绪队列中,或每个处理器都有它自己的私有就绪进程队列。不管如何,调度这样进行:每个处理器的调度程序都检查共同就绪队列,以便选择执行一个进程。如果多个处理器试图访问和更新一个共同的数据结构,那么每个处理器必须仔细编程,必须确保两个处理器不会选择同一进程,而且进程不会从队列中丢失。
几乎所有现代操作系统,包括 Windows、Linux 和 Mac OSX,都支持 SMP。本节余下部分讨论有关 SMP 系统的多个问题。
处理器亲和性
考虑一下,当一个进程运行在一个特定处理器上时缓存会发生些什么。进程最近访问的数据更新了处理器的缓存。结果,进程的后续内存访问通常通过缓存来满足。现在考虑一下,如果进程移到其他处理器上则会发生什么。第一个处理器缓存的内容应设为无效,第二个处理器缓存应重新填充。由于缓存的无效或重新填充的代价高,大多数 SMP 系统试图避免将进程从一个处理器移到另一个处理器,而是试图让一个进程运行在同一个处理器上。这称为处理器亲和性,即一个进程对它运行的处理器具有亲和性。
处理器的亲和性具有多种形式。当一个操作系统试图保持进程运行在同一处理器上时(但不保证它会这么做),这种情况称为软亲和性。这里,操作系统试图保持一个进程在某个处理器上,但是这个进程也可迁移到其他处理器。相反,有的系统提供系统调用以便支持硬亲和性,从而允许某个进程运行在某个处理器子集上。
许多系统提供软的和硬的亲和性。例如,Linux 实现软亲和性,但是它也提供系统调用 sched_setaffinity() 以支持硬亲和性。
图 1 NUMA 与 CPU 调度
系统的内存架构可以影响处理器的亲和性。图 1 为采用非统一内存访问的一种架构,其中一个 CPU 访问内存的某些部分会比其他部分更快。通常情况下,这类系统包括组合 CPU 和内存的板卡。每个板的 CPU 访问本板内存快于访问其他板的内存。
如果操作系统的 CPU 调度和内存分配算法一起工作,那么当一个进程分配到一个特定的亲和处理器时,它应分配到同板上的内存。这个例子还说明操作系统通常不按教科书描述的那样清楚地定义与实现。实际上,操作系统的各个部分的“实线”通常应是“虚线”,因为有些算法创建连接以便优化性能和可靠性。
负载平衡
对于 SMP 系统,重要的是保持所有处理器的负载平衡,以便充分利用多处理器的优点。否则,一个或多个处理器会空闲,而其他处理器会处于高负载状态,且有一系列进程处于等待状态。负载平衡设法将负载平均分配到 SMP 系统的所有处理器。需要注意的是,对于有些系统(它们的处理器具有私有的可执行进程的队列),负载平衡是必需的;而对于具有公共队列的系统,负载平衡通常没有必要,因为一旦处理器空闲,它立刻从公共队列中取走一个可执行进程。同时,要注意对于大多数支持SMP的现代操作系统,每个处理器都有一个可执行进程的私有队列。
负载平衡通常有两种方法:推迁移和拉迁移:
- 对于推迁移,一个特定的任务周期性地检查每个处理器的负载,如果发现不平衡,那么通过将进程从超载处理器推到空闲或不太忙的处理器,从而平均分配负载。
- 当空闲处理器从一个忙的处理器上拉一个等待任务时,发生拉迁移。
推迁移和拉迁移不必相互排斥,事实上,在负载平衡系统中它们常被并行实现。例如,Linux 调度程序和用于 FreeBSD 系统的 ULE 调度程序实现了这两种技术。
有趣的是,负载平衡往往会抵消处理器亲和性的好处。也就是说,保持一个进程运行在同一处理器上的好处是进程可以利用它在该处理器缓存内的数据。无论是从一个处理器向另一处理器推或拉进程,都会失去这个好处。
与通常的系统工程情况一样,关于何种方式是最好的,没有绝对规则。因此,在某些系统中,空闲的处理器总是会从非空闲的处理器中拉进程;而在其他系统中,只有当不平衡达到一定程度后才会移动进程。
多核处理器
传统上,SMP 系统具有多个物理处理器,以便允许多个线程并行运行。然而,计算机硬件的最近做法是,将多个处理器放置在同一个物理芯片上,从而产生多核处理器。每个核都保持架构的状态,因此对操作系统而言它似乎是一个单独的物理处理器。采用多核处理器的 SMP 系统与采用单核处理器的 SMP 系统相比,速度更快,功耗更低。多核处理器的调度问题可能更为复杂。下面我们来分析一下原因。
研究人员发现,当一个处理器访问内存时,它花费大量时间等待所需数据。这种情况称为内存停顿,它的发生原因多种多样,如高速缓存未命中(访问数据不在高速缓冲里)。图 2 显示了内存停顿。
图 2 内存停顿
在这种情况下,处理器可能花费高达 50% 的时间等待内存数据变得可用。为了弥补这种情况,许多最近的硬件设计都采用了多线程的处理器核,即每个核会分配到两个(或多个)硬件线程。这样,如果一个线程停顿而等待内存,该核可以切换到另一个线程。图 3 显示了一个双线程的处理器核,这里线程 0 和线程 1 的执行是交错的。
图 3 多线程多核系统
从操作系统的角度来看,每一个硬件线程似乎作为一个逻辑处理器,以便运行软件线程。因此,在双线程双核系统中,操作系统会有 4 个逻辑处理器。UltraSPARC T3 CPU 具有 16 个处理器核,而每个核有 8 个硬件线程,从操作系统的角度,就有 128 个逻辑处理器。
一般来说,处理器核的多线程有两种方法:粗粒度和细粒度的多线程。
对于粗粒度的多线程,线程一直在处理器上执行,直到一个长延迟事件(如内存停顿)发生。由于长延迟事件造成的延迟,处理器应切换到另一个线程来开始执行。然而,线程之间的切换成本是高的,因为在另一个线程可以在处理器核上开始执行之前,应刷新指令流水线。一旦这个新的线程开始执行,它会开始用指令来填充流水线。
细粒度(或交错)的多线程在更细的粒度级别上(通常在指令周期的边界上)切换线程。而且,细粒度系统的架构设计有线程切换的逻辑。因此,线程之间的切换成本很小。
注意,一个多线程多核处理器实际需要两个不同级别的调度。一个级别的调度决策由操作系统做出,用于选择哪个软件线程运行在哪个硬件线程(逻辑处理器)。对于这个级别的调度,操作系统可以选择任何调度算法。
另一个级别的调度指定每个核如何决定运行哪个硬件线程。在这种情况下,有多种策略可以采用。前面提到的 UltraSparc T3 采用一个简单的轮转算法,安排 8 个硬件线程到每个核。
再比如,Intel Itanium 为双核处理器,而且每个核有两个硬件线程。每个硬件线程有一个动态的紧迫值,它的取值范围为 0〜7,用 0 表示最低的紧迫性,而 7 表示最高的。Itanium 有 5 个不同的事件,用于触发线程切换。当这些事件发生时,线程切换逻辑会比较两个线程的紧迫性,并选择紧迫性较高的线程在处理器核上执行。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算