搜索引擎抓取网页的流程
搜索引擎对网页的抓取实质上就是搜索蜘蛛(Spider)或机器人(Robot)在整个互联网平台上进行信息的采集和抓取,这也是搜索引擎最基本的工作。
搜索引擎蜘蛛/机器人采集的力度直接决定了搜索引擎前端检索器可提供的信息量及信息覆盖面,同时影响反馈给用户检索查询信息的质量。所以,搜索引擎本身在不断设法提高其数据采集/抓取及分析的能力。
本文将着重介绍搜索引擎抓取页面的流程及方式。
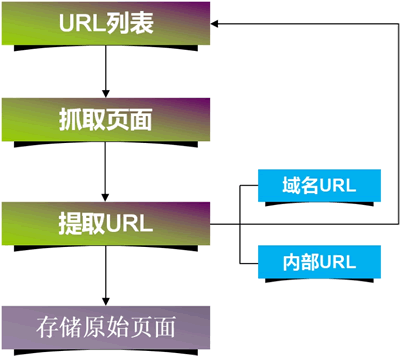
图1:搜索引擎抓取/收录页面的流程
URL 是页面的入口地址,域名则是整个网站的入口。搜索引擎蜘蛛程序会通过域名进入网站,然后对网站内的页面实施抓取。
如图1所示,蜘蛛程序会从原始 URL 列表出发,通过 URL 抓取页面,然后从该页面提取新的 URL 存储到原始 URL 列表中(这个步骤会不断地重复,周而复始地累积扩大原始 URL 资源库),最后将该原始页面存储到搜索引擎索引库。
蜘蛛程序的执行步骤可以按照如下分拆步骤理解。
如何让网站被搜索引擎收录呢?
方法①:主动向搜索引擎提交 URL(此方法快则一周,慢则一月才会被收录)。
常用搜索引擎提交入口如下:
方法②:与其他网站建立链接关系,即“外链”。
使搜索引擎能够通过外部网站发现我们的网站,实现页面收录(该方法主要看外部网站链接的质量、数量及相关性,相较主动向搜索引擎提交 URL,速度快很多,一般一周左右)。
域名 URL 即网站首页地址,如 www.xinbaoku.com;内部 URL 即网站内部各页面的地址,如 https://www.xinbaoku.com/archive/zDtAcMFz.html。蜘蛛所提取的 URL 资源会持续添加到 URL 列表。
然而,在互联网这片浩瀚的信息汪洋中,搜索引擎又怎样保证快速、有效地抓取更多的相对重要的页面呢?这就需要我们接着来了解搜索引擎的抓取方式。
了解搜索引擎的抓取方式有利于我们建立对搜索引擎友好的网站结构,使搜索引擎蜘蛛能够在我们网站上停留的时间更久,抓取更多的网站页面(即收录数量),为网站关键词排名提供有力支撑。
常见的搜索引擎抓取页面的方式有广度优先抓取、深度优先抓取、质量优先抓取、暗网抓取。
广度优先抓取是最常用的蜘蛛抓取方式,该方法的优点是可以让网络蜘蛛并行处理,提高其抓取速度。
广度优先抓取是一种按层次横向抓取页面的方式,如图2所示,它会从网页的最底层,也就是首页开始抓取页面,直至该层页面被抓取完才会进入下一层。
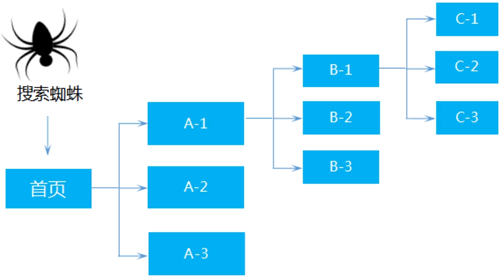
图2:广度优先抓取的爬行策略
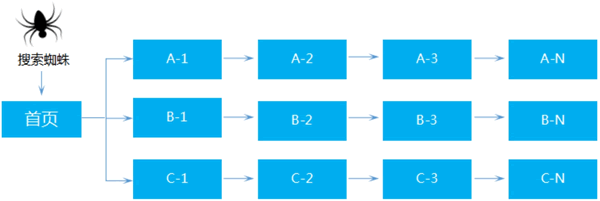
图3:深度优先抓取的爬行策略
搜索引擎整理高质量的网站一般分为两种方式:
搜索引擎爬虫必须依赖页面中的链接关系发现新的页面,但是很多网站的内容是以数据库方式存储的,典型的例子是一些垂直领域网站,如携程旅行网的机票数据,很难使用显式链接指向数据库内的所有机票记录,往往是服务网站提供组合查询界面(如图4所示),只有用户按照需求输入查询之后,才能够获得相关数据。所以,常规的爬虫无法索引这些数据内容,这是暗网的命名由来。
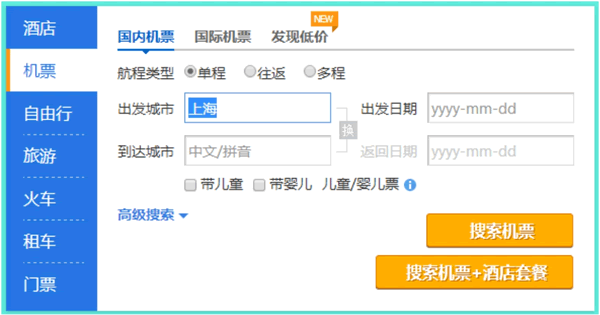
图4:携程网机票搜索框
为了能够对暗网数据进行索引,需要研发与常规爬虫机制不同的系统,这类爬虫被称作暗网爬虫。暗网爬虫的目的是将暗网数据从数据库中挖掘出来,并将其加入搜索引擎的索引,这样用户在搜索时便可利用这些数据增加信息覆盖程度。
搜索引擎蜘蛛/机器人采集的力度直接决定了搜索引擎前端检索器可提供的信息量及信息覆盖面,同时影响反馈给用户检索查询信息的质量。所以,搜索引擎本身在不断设法提高其数据采集/抓取及分析的能力。
本文将着重介绍搜索引擎抓取页面的流程及方式。
1. 页面收录/抓取流程
在整个互联网中,URL 是每个页面的入口地址,同时搜索引擎蜘蛛程序也是通过 URL 来抓取网站页面的,整个流程如图1所示。图1:搜索引擎抓取/收录页面的流程
URL 是页面的入口地址,域名则是整个网站的入口。搜索引擎蜘蛛程序会通过域名进入网站,然后对网站内的页面实施抓取。
如图1所示,蜘蛛程序会从原始 URL 列表出发,通过 URL 抓取页面,然后从该页面提取新的 URL 存储到原始 URL 列表中(这个步骤会不断地重复,周而复始地累积扩大原始 URL 资源库),最后将该原始页面存储到搜索引擎索引库。
蜘蛛程序的执行步骤可以按照如下分拆步骤理解。
1) 蜘蛛发现网站
搜索引擎的爬行程序(俗称蜘蛛)发现网站,来到网站上。也就是说,网站首先要存在且能够被蜘蛛发现。比如新宝库如果想要被搜索引擎收录,首先网站要存在而且必须有内容。如何让网站被搜索引擎收录呢?
方法①:主动向搜索引擎提交 URL(此方法快则一周,慢则一月才会被收录)。
常用搜索引擎提交入口如下:
- 百度:http://zhanzhang.baidu.com/linksubmit/url
- 360搜索:http://info.so.360.cn/site_submit.html
- 搜狗:http://zhanzhang.sogou.com/index.php/urlSubmit/index
- 谷歌:https://www.google.com/webmasters/tools/submit-url?pli=1
- 必应:http://www.bing.com/toolbox/submit-site-url
方法②:与其他网站建立链接关系,即“外链”。
使搜索引擎能够通过外部网站发现我们的网站,实现页面收录(该方法主要看外部网站链接的质量、数量及相关性,相较主动向搜索引擎提交 URL,速度快很多,一般一周左右)。
2) 蜘蛛抓取入口页面
蜘蛛开始对入口页面进行抓取,并存储入口的原始页面,包含页面的抓取时间、URL、最后修改时间等。存储原始页面的目的是为了下次比对页面是否有更新,为保证采集的资料最新,它还会回访已抓取过的网页。3) 提取 URL
提取 URL 包含两方面的内容:提取域名 URL 和提取内部 URL。域名 URL 即网站首页地址,如 www.xinbaoku.com;内部 URL 即网站内部各页面的地址,如 https://www.xinbaoku.com/archive/zDtAcMFz.html。蜘蛛所提取的 URL 资源会持续添加到 URL 列表。
2. 页面抓取方式
相信通过上述内容,大家对搜索引擎的抓取原理及流程有了一个大致的了解。然而,在互联网这片浩瀚的信息汪洋中,搜索引擎又怎样保证快速、有效地抓取更多的相对重要的页面呢?这就需要我们接着来了解搜索引擎的抓取方式。
了解搜索引擎的抓取方式有利于我们建立对搜索引擎友好的网站结构,使搜索引擎蜘蛛能够在我们网站上停留的时间更久,抓取更多的网站页面(即收录数量),为网站关键词排名提供有力支撑。
常见的搜索引擎抓取页面的方式有广度优先抓取、深度优先抓取、质量优先抓取、暗网抓取。
1) 广度优先抓取
广度优先抓取是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。广度优先抓取是最常用的蜘蛛抓取方式,该方法的优点是可以让网络蜘蛛并行处理,提高其抓取速度。
广度优先抓取是一种按层次横向抓取页面的方式,如图2所示,它会从网页的最底层,也就是首页开始抓取页面,直至该层页面被抓取完才会进入下一层。
提示:当我们在做网站优化的时候,不妨将一些相对重要的信息或栏目在首页优先展示出来(如热门产品、资讯内容等),让搜索引擎优先抓取到网站较为重要的信息。
图2:广度优先抓取的爬行策略
2) 深度优先抓取
深度优先抓取是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接,如图3所示。图3:深度优先抓取的爬行策略
3) 质量优先抓取
质量优先抓取一般是针对大型网站,比如新浪、网易、阿里巴巴等类型的网站,由于它们的信息量庞大,而且本身权重比较高,相对来说更容易为用户提供更有价值的信息。正因如此,搜索引擎会更愿意优先抓取大型网站中的网页,以保障其可以在最短的时间内为用户提供更有价值的信息(这也是大型网站的内容抓取比小站更及时的原因之一)。搜索引擎整理高质量的网站一般分为两种方式:
- 一种是前期的人工整理大量种子网站,进而由种子资源出发去发现更多大型网站资源;
- 另一种是对已经索引的网站进行系统分析,从而识别那些内容丰富、规模较大、信息更新频繁的网站。
4) 暗网抓取
所谓暗网(又称深网、不可见网或隐藏网),是指目前搜索引擎爬虫按照常规方式很难抓取到的互联网页面。搜索引擎爬虫必须依赖页面中的链接关系发现新的页面,但是很多网站的内容是以数据库方式存储的,典型的例子是一些垂直领域网站,如携程旅行网的机票数据,很难使用显式链接指向数据库内的所有机票记录,往往是服务网站提供组合查询界面(如图4所示),只有用户按照需求输入查询之后,才能够获得相关数据。所以,常规的爬虫无法索引这些数据内容,这是暗网的命名由来。
图4:携程网机票搜索框
为了能够对暗网数据进行索引,需要研发与常规爬虫机制不同的系统,这类爬虫被称作暗网爬虫。暗网爬虫的目的是将暗网数据从数据库中挖掘出来,并将其加入搜索引擎的索引,这样用户在搜索时便可利用这些数据增加信息覆盖程度。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算