操作系统组织数据的方法(详解版)
下面讨论操作系统实现的一个核心问题:系统如何组织数据。本节简要讨论多个基本数据结构,它们在操作系统中用得很多。
在计算机科学中,除了数组,列表可能是最为重要的数据结构。不过,数组的项可以直接访问,而列表的项需要按特定次序来访问。即列表(list)将一组数据表示成序列。实现这种结构的最常用方法是链表(linked list),项与项是链接起来的。链表包括多个类型:

图 1 单向链表

图 2 双向链表

图 3 循环链表
链表允许不同大小的项,各项的插入与删除也很方便。链表的使用有一个潜在缺点:在大小为 n 的链表中,获得某一特定项的性能是线性的,即
堆栈(stack)作为有序数据结构,在增加和删除数据项时采用后进先出(Last In First Out,LIFO)的原则,即最后增加到堆栈的项是第一个被删除的。堆栈的项的插入和删除,分别称为压入(push)和弹出(pop)。
操作系统在执行函数调用时,经常采用堆栈。当调用函数时,参数、局部变量及返回地址首先压人堆栈;当从函数调用返回时,会从堆栈上弹出这些项。
相反,队列(queue)作为有序数据结构,采用先进先出(First in First Out,FIFO)的原则:删除队列的项的顺序与插入的顺序一致。
日常生活的队列样例有很多,如商店客户排队等待结账,汽车排队等待信号灯。操作系统的队列也有很多,例如,送交打印机的作业通常按递交顺序来打印,等待 CPU 的任务通常按队列来组织。
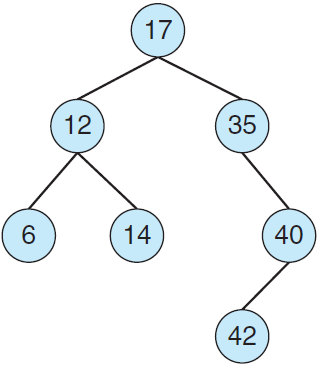
图 4 二叉查找树
图 4 为一个二叉查找树的例子。当需要对一个二叉查找树进行查找时,最坏性能为
哈希函数有一潜在问题:两个输入可能产生同样的输出值,即它们会链接到列表的同一位置。哈希碰撞(hash collision)可以这样处理:在列表位置上可以存放一个链表,以便将具有相同哈希值的所有项链接起来。当然,碰撞越多,哈希函数的效率越低。
哈希函数的另一用途是实现哈希表(hash map),即利用哈希函数将键(key)和值 (value)关联起来。例如,可将键 operating 映射到值 system。有了这个映射,就可将哈希函数应用于键,进而从哈希表中获得对应值(图 5)。
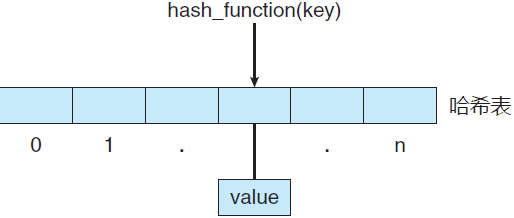
图 5 哈希映射
例如,现有用户名称映射到用户密码。 用户认证可以这样进行:用户输入他的用户名称和密码;将哈希函数应用于用户名称,以获取密码;获取密码再与用户输入的密码进行比较,以便认证。
例如,现有如下位图:
当考虑空间效率时,位图优势明显。如果所用的布尔值是 8 位的而不是 1 位的,那么最终的数据结构将会是原来的 8 倍。因此,当需要表示大量资源的可用性时,通常采用位图。磁盘驱动器就是这么工作的。一个中等大小的磁盘可以分成数千个单元,称为磁盘块(disk block)。每个磁盘块的可用性就可通过位图来表示。
数据结构广泛用于实现操作系统。因此,除了这里讨论的一些数据结构,在分析内核算法与实现时,也会讨论其他的数据结构。
列表、堆栈及队列
数组是个简单的数据结构,它的元素可被直接访问。例如,内存就是一个数组。如果所存的数据项大于一字节,那么可用多个字节来保存数据项,并可按项码 x 项大小(item number X item size)来寻址。不过,如何保存可变大小的项?再者,如何删除一项而不影响其他项的相对位置?对于这些情况,数组不如其他数据结构。在计算机科学中,除了数组,列表可能是最为重要的数据结构。不过,数组的项可以直接访问,而列表的项需要按特定次序来访问。即列表(list)将一组数据表示成序列。实现这种结构的最常用方法是链表(linked list),项与项是链接起来的。链表包括多个类型:
- 单向链表(singly linked list)的每项指向它的后继,如图 1 所示:
图 1 单向链表
- 双向链表(doubly linked list)的每项指向它的前驱与后继,如图 2 所示:
图 2 双向链表
- 循环链表(circularly linked list)的最后一项指向第一项(而不是设为 null),如图 3 所示:
图 3 循环链表
链表允许不同大小的项,各项的插入与删除也很方便。链表的使用有一个潜在缺点:在大小为 n 的链表中,获得某一特定项的性能是线性的,即
O(n),这是由于在最坏情况下需要遍历所有的 n 个元素。列表有时直接用于内核算法,不过,更多的是用于构造更为强大的数据结构,如堆栈和队列等。堆栈(stack)作为有序数据结构,在增加和删除数据项时采用后进先出(Last In First Out,LIFO)的原则,即最后增加到堆栈的项是第一个被删除的。堆栈的项的插入和删除,分别称为压入(push)和弹出(pop)。
操作系统在执行函数调用时,经常采用堆栈。当调用函数时,参数、局部变量及返回地址首先压人堆栈;当从函数调用返回时,会从堆栈上弹出这些项。
相反,队列(queue)作为有序数据结构,采用先进先出(First in First Out,FIFO)的原则:删除队列的项的顺序与插入的顺序一致。
日常生活的队列样例有很多,如商店客户排队等待结账,汽车排队等待信号灯。操作系统的队列也有很多,例如,送交打印机的作业通常按递交顺序来打印,等待 CPU 的任务通常按队列来组织。
树
树(tree)是一种数据结构,可以表示数据层次。树结构的数据值可按父-子关系连接起来。对于一般树(general tree),父结点可有多个子结点。对于二叉树(binary tree),父结点最多可有两个子结点,即左子结点(left child)和右子结点(right child)。二叉查找树(binary search tree)还要求对两个子结点进行排序,如左子结点 ≤ 右子结点。图 4 二叉查找树
图 4 为一个二叉查找树的例子。当需要对一个二叉查找树进行查找时,最坏性能为
O(n)(请想一想这是为什么)。为了纠正这种情况,我们可以通过算法来创建平衡二叉查找树(balanced binary search tree)。这样,包含 n 个项的树最多只有 lgn 层,这可确保最坏性能为 O(lgn)。在后续章节中,我们还将会看到,Linux 在 CPU 调度算法中就使用了平衡二叉查找树。哈希函数与哈希表
哈希函数(hash function)将一个数据作为输入,对此进行数值运算,然后返回一个数值。该值可用作一个表(通常为数据组)的索引,以快速获得数据。虽然在最坏情况下从大小为n的列表中查找数据项所需的比较会是O(n),但是采用哈希函数来从表中获得数据可能只有 O(1),这与具体实现有关。由于性能关系,哈希函数在操作系统中用得很广。哈希函数有一潜在问题:两个输入可能产生同样的输出值,即它们会链接到列表的同一位置。哈希碰撞(hash collision)可以这样处理:在列表位置上可以存放一个链表,以便将具有相同哈希值的所有项链接起来。当然,碰撞越多,哈希函数的效率越低。
哈希函数的另一用途是实现哈希表(hash map),即利用哈希函数将键(key)和值 (value)关联起来。例如,可将键 operating 映射到值 system。有了这个映射,就可将哈希函数应用于键,进而从哈希表中获得对应值(图 5)。
图 5 哈希映射
例如,现有用户名称映射到用户密码。 用户认证可以这样进行:用户输入他的用户名称和密码;将哈希函数应用于用户名称,以获取密码;获取密码再与用户输入的密码进行比较,以便认证。
位图
位图(bitmap)为 n 个二进制位的串,用于表示 n 项的状态。例如,假设有若干资源,每个资源的可用性可用二进制数字来表示:0 表示资源可用,而 1 表示资源不可用(或相反)。位图的第 i 个位置的值与第 i 个资源相关联。例如,现有如下位图:
001011101
第 2、4、5、6 和 8 个资源是不可用的,第 0、1、3 和 7 个资源是可用的。当考虑空间效率时,位图优势明显。如果所用的布尔值是 8 位的而不是 1 位的,那么最终的数据结构将会是原来的 8 倍。因此,当需要表示大量资源的可用性时,通常采用位图。磁盘驱动器就是这么工作的。一个中等大小的磁盘可以分成数千个单元,称为磁盘块(disk block)。每个磁盘块的可用性就可通过位图来表示。
数据结构广泛用于实现操作系统。因此,除了这里讨论的一些数据结构,在分析内核算法与实现时,也会讨论其他的数据结构。
知识扩展:Linux 内核所用的数据结构有源码。头文件 <linux/list.h> 包括内核所用的链表数据结构的实现细节。Linux 的队列称为 kfifo,源代码的目录 kernel 的文件 kfifo.c 包含它的实现。Linux 通过红黑树提供了平衡二分查找树的实现,头文件 <linux/rbtree.h> 包括它的细节。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算