面向过程程序设计(结构化程序设计)的不足
结构化程序设计也叫面向过程的程序设计,它和面向对象的程序设计是相对的。
结构化程序设计的基本思想是自顶向下、逐步求精,即将复杂的大问题层层分解为许多简单的小问题的组合。整个程序被划分成多个功能模块,不同的模块可以由不同的人员进行开发,只要合作者之间规定好模块之间相互通信和协作的接口即可。
例如,一个大型的网络游戏可以分成动画引擎、地图绘制、人工智能策略、游戏角色管理、用户账户管理、网络通信协议等诸多模块。不同模块可以分别由不同的小组开发,每个模块都要对外提供一个接口(一般就是函数和全局变量的集合),以便其他模块能够调用自己提供的功能。
例如,人工智能策略模块可能会提供在地图上寻找路径的功能,地图绘制模块需要提供查询道路和障碍物、建筑物位置的功能,这个功能会被人工智能策略模块中的寻找路径子模块调用,游戏人物需要前进时,就会调用人工智能策略模块提供的寻找路径的函数来决定下一步如何行走。
计算机界最高奖“图灵奖”得主、Pascal 语言发明人沃斯教授有一个著名的公式,就是:
在结构化程序设计中,算法和数据结构是分离的,没有直观的手段能够说明一个算法操作了哪些数据结构,一个数据结构又是由哪些算法来操作的。当数据结构的设计发生变化时,分散在整个程序各处的、所有操作该数据结构的算法都需要进行修改。
结构化程序设计也没有提供手段来限制数据结构可被操作的范围,任何算法都可以操作任何数据结构,这容易造成算法由于编写失误,对关键数据结构进行错误的操作而导致程序出现严重问题甚至崩溃。
结构化程序设计也称为面向过程的程序设计。过程是用函数实现的。因此,结构化程序设计归根到底要考虑的就是如何将整个程序分成一个个函数,哪些函数之间要互相调用,以及每个函数内部将如何实现。
此外,结构化程序设计难免要使用一些全局变量来存储数据,如一个网络游戏一般会以一些全局变量来记录当前战场上有多少个玩家,每个角色在地图上的位置等。这些全局变量往往会被很多函数访问或修改,如选择角色前进路径的函数可能就会需要知道当前地图上有哪些敌人以及敌人的位置。
在程序规模庞大的情况下,程序中可能有成千上万个函数、成百上千个全局变量,要搞清楚函数之间的调用关系,以及哪些函数会访问哪些全局变量,是很麻烦的事情。
下图所示为结构化程序的模式,Sub 代表一个个函数,箭头代表“访问”或“调用”。
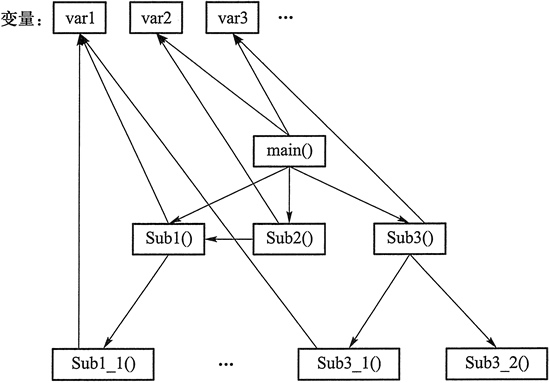
图:结构化程序的模式
在这种情况下,当某项数据的值不正确时,很难找出到底是哪个函数导致的,因而程序的查错也变得困难。
但是在结构化程序设计中,随着程序规模的增大,大量函数、变量之间的关系错综复杂,要抽取可重用的代码往往变得十分困难。
例如,要重用一个函数,可是这个函数又调用一些新程序用不到的其他函数,因此就不得不将其他函数也一并抽取出来;更糟糕的是,也许想重用的函数访问了某些全局变量,这样还要将不相干的全局变量也抽取出来,或者修改被重用的函数以去掉对全局变量的访问。
总之,结构化的程序中各个模块之间耦合度高,有千丝万缕牵扯不清的联系,想要重用某个模块,就像是在杂乱摆放着一大堆设备的电脑桌上拿走笔记本电脑的电源适配器一样,拿起电源适配器,它的连接线却扯出一大堆乱七八糟的音箱、耳机、鼠标、外接光驱等东西。
总之,结构化的程序在规模庞大时会变得难以理解,难以扩充,难以查错,难以重用。
随着软件规模的不断扩大,结构化程序设计越来越难以适应软件开发的需要。此时,面向对象的程序设计方法就应运而生了。
结构化程序设计的基本思想是自顶向下、逐步求精,即将复杂的大问题层层分解为许多简单的小问题的组合。整个程序被划分成多个功能模块,不同的模块可以由不同的人员进行开发,只要合作者之间规定好模块之间相互通信和协作的接口即可。
例如,一个大型的网络游戏可以分成动画引擎、地图绘制、人工智能策略、游戏角色管理、用户账户管理、网络通信协议等诸多模块。不同模块可以分别由不同的小组开发,每个模块都要对外提供一个接口(一般就是函数和全局变量的集合),以便其他模块能够调用自己提供的功能。
例如,人工智能策略模块可能会提供在地图上寻找路径的功能,地图绘制模块需要提供查询道路和障碍物、建筑物位置的功能,这个功能会被人工智能策略模块中的寻找路径子模块调用,游戏人物需要前进时,就会调用人工智能策略模块提供的寻找路径的函数来决定下一步如何行走。
计算机界最高奖“图灵奖”得主、Pascal 语言发明人沃斯教授有一个著名的公式,就是:
数据结构 + 算法 = 程序
这精辟地概括了结构化程序设计的特点。数据结构和变量相对应,算法和函数相对应,算法是用来操作数据结构的。在结构化程序设计中,算法和数据结构是分离的,没有直观的手段能够说明一个算法操作了哪些数据结构,一个数据结构又是由哪些算法来操作的。当数据结构的设计发生变化时,分散在整个程序各处的、所有操作该数据结构的算法都需要进行修改。
结构化程序设计也没有提供手段来限制数据结构可被操作的范围,任何算法都可以操作任何数据结构,这容易造成算法由于编写失误,对关键数据结构进行错误的操作而导致程序出现严重问题甚至崩溃。
结构化程序设计也称为面向过程的程序设计。过程是用函数实现的。因此,结构化程序设计归根到底要考虑的就是如何将整个程序分成一个个函数,哪些函数之间要互相调用,以及每个函数内部将如何实现。
此外,结构化程序设计难免要使用一些全局变量来存储数据,如一个网络游戏一般会以一些全局变量来记录当前战场上有多少个玩家,每个角色在地图上的位置等。这些全局变量往往会被很多函数访问或修改,如选择角色前进路径的函数可能就会需要知道当前地图上有哪些敌人以及敌人的位置。
在程序规模庞大的情况下,程序中可能有成千上万个函数、成百上千个全局变量,要搞清楚函数之间的调用关系,以及哪些函数会访问哪些全局变量,是很麻烦的事情。
下图所示为结构化程序的模式,Sub 代表一个个函数,箭头代表“访问”或“调用”。
图:结构化程序的模式
结构化程序在规模变大时会难以理解和维护。
在结构化的程序中,函数和其所操作的数据(全局变量)之间的关系没有清晰和直观的体现。随着程序规模的增加,程序逐渐难以理解,很难一下子看出来函数之间存在怎样的调用关系,某项数据到底有哪些函数可以对它进行操作,某个函数到底是用来操作哪些数据的。在这种情况下,当某项数据的值不正确时,很难找出到底是哪个函数导致的,因而程序的查错也变得困难。
结构化的程序不利于修改和扩充(增加新功能)。
结构化程序设计没有“封装”和“隐藏”的概念,要访问某个变量时可以直接访问,当该变量的定义有改动时,就要把所有访问该变量的语句找出来修改,这些语句可能分散在上百个函数之中,这显然十分费时费力。结构化程序不利于代码的重用。
在编写某个程序时,常常会发现其需要的某项功能在现有的某个程序中已经有了相同或类似的实现,因而自然希望能够将那部分源代码抽取出来,在新程序中使用,这就叫代码的重用。但是在结构化程序设计中,随着程序规模的增大,大量函数、变量之间的关系错综复杂,要抽取可重用的代码往往变得十分困难。
例如,要重用一个函数,可是这个函数又调用一些新程序用不到的其他函数,因此就不得不将其他函数也一并抽取出来;更糟糕的是,也许想重用的函数访问了某些全局变量,这样还要将不相干的全局变量也抽取出来,或者修改被重用的函数以去掉对全局变量的访问。
总之,结构化的程序中各个模块之间耦合度高,有千丝万缕牵扯不清的联系,想要重用某个模块,就像是在杂乱摆放着一大堆设备的电脑桌上拿走笔记本电脑的电源适配器一样,拿起电源适配器,它的连接线却扯出一大堆乱七八糟的音箱、耳机、鼠标、外接光驱等东西。
总之,结构化的程序在规模庞大时会变得难以理解,难以扩充,难以查错,难以重用。
随着软件规模的不断扩大,结构化程序设计越来越难以适应软件开发的需要。此时,面向对象的程序设计方法就应运而生了。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算