Python编码规范的重要性
很多去 Google 参观的人,在用完洗手间后都有这样的疑惑,马桶前面的门上怎么会贴着 Python 编码规范?要知道,Google 对编码规范的要求极其严格,这也能从侧面说明编码规范的重要性。
对于编码规范的认知,很多初学者还仅停留在初级阶段,即只知道编码规范有用,比如命名时使用驼峰式的格式(如 TheFirstDemo),而至于为什么要求这样严格,就不是很清楚了。
本节,将给读者扫除以下 2 个盲区:
注意,在讲解过程,会引用以下 2 个编码规范来举例,分别是:
以上这 2 个编码规范,Google Style 比 PEP8 更为严格,因为 PEP8 的主要面向群体是个人和小团队开发者,而 Google Style 则能够胜任大团队甚至是企业。
而影响开发效率的有 3 类对象,分别是阅读者、编程者和机器,它们的优先级是阅读者>>编程者>>机器(>>表示远远大于)。
因此,如果想提高开发效率,首先要优化的不是码代码的速度,而是阅读代码的体验。
其实,很多编码规范本身就是为优化读者体验而存在的,拿命名原则来说,PEP8 第 38 条规定命名不能是无意义的单字母,有意义的名称可以很大程序提高阅读者的体验。
例如,阅读如下这行程序:
例如,PEP8 和 Google Style 都特别强调了,何时使用 is, 何时使用 ==,何时使用隐式布尔转换。不仅如此,Google Style 2.8 还对遍历方式的选择作出了明确限制。
在编程过程中,只要严格遵守编码规范,编写出的代码通常都很健壮,可移植性也很高。
首先,你需要根据自己的具体工作环境,选择或者制定适合自己公司或团队的编码规范。市面上可以参考的规范,也就是在文章开头提到的 PEP8 和 Google Style。
要知道,没有放之四海而皆准的规范,我们必须要因地制宜。例如在 Google 中,因为历史原因 C++ 不使用异常,引入异常对整个代码库带来的风险已经远大于它的益处,所以在它的 C++ 代码规范中,禁止使用异常。
一旦确定了整个团队所遵从的编码规范,就一定要强制执行,有什么好的办法呢?靠强制代码评审和强制静态或者动态 linter。具体流程是:
整合之后,你的团队工作流程就会变成图 1 所示的这样。
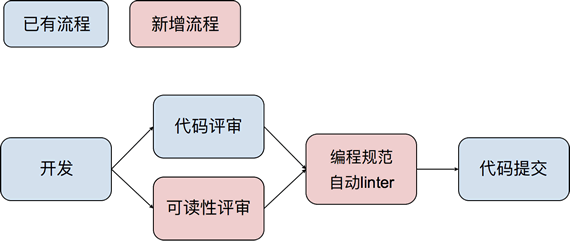
图 1 自动检查编码规范的工作流程
学到这里,相信你对代码风格的重要性有了全新的认识。
对于编码规范的认知,很多初学者还仅停留在初级阶段,即只知道编码规范有用,比如命名时使用驼峰式的格式(如 TheFirstDemo),而至于为什么要求这样严格,就不是很清楚了。
本节,将给读者扫除以下 2 个盲区:
- Python 编码规范到底有多么重要,它对于业务开发来说,究竟有哪些帮助?
- 有哪些流程和工具,可以强制你遵循规定好的编码规范呢?
注意,在讲解过程,会引用以下 2 个编码规范来举例,分别是:
- 《8 号 Python 增强规范》,通常称之为 PEP8;
- 《Google Python 风格规范》 简称为 Google Style,这是源自 Google 内部公开发布的社区版本,其目的是为了让 Google 旗下所有 Python 开源项目的编程风格统一。
以上这 2 个编码规范,Google Style 比 PEP8 更为严格,因为 PEP8 的主要面向群体是个人和小团队开发者,而 Google Style 则能够胜任大团队甚至是企业。
Python编码规范到底有多么重要
Python 编码规范重要性的原因用一句话来概括就是:统一的编码规范可以提高开发效率。而影响开发效率的有 3 类对象,分别是阅读者、编程者和机器,它们的优先级是阅读者>>编程者>>机器(>>表示远远大于)。
阅读者>>编程者
写过代码的人应该深有体会,在实际工作中真正用来码代码的时间,远比阅读或者调试的时间要少。事实也是如此,有研究表明,软件工程中 80% 的时间都在阅读代码。因此,如果想提高开发效率,首先要优化的不是码代码的速度,而是阅读代码的体验。
其实,很多编码规范本身就是为优化读者体验而存在的,拿命名原则来说,PEP8 第 38 条规定命名不能是无意义的单字母,有意义的名称可以很大程序提高阅读者的体验。
编程者>>机器
说完了阅读者的体验,再来聊聊编程者的体验。笔者常常见到的一个错误倾向就是过度简化自己的代码,这样做会大大降低代码的可阅读性,并且一旦出现 BUG,也不容易检查出来。例如,阅读如下这行程序:
result = [(x, y) for x in range(10) for y in range(5) if x * y > 10]上面这行代码还可以改写成如下这种形式:
result = []
for x in range(10):
for y in range(5):
if x * y > 10:
result.append((x, y))
对比这 2 种写法,显然后者调理更清楚,更容易理解,编写起来也更轻松。以上代码,涉及到了列表和判断循环结构的相关知识,由于还未学到,初学者不需要理解。
机器体验也很重要
每个人都希望自己编写的代码能正确、高效地在电脑上执行,但是一些危险的编程风格,不仅会影响程序的正确性,也容易成为代码效率的瓶颈。例如,PEP8 和 Google Style 都特别强调了,何时使用 is, 何时使用 ==,何时使用隐式布尔转换。不仅如此,Google Style 2.8 还对遍历方式的选择作出了明确限制。
在编程过程中,只要严格遵守编码规范,编写出的代码通常都很健壮,可移植性也很高。
编码规范的自动化工具
既然编码规范的终极目标是提高开发效率。所以,如果每次写代码都需要在代码规范上额外花很多时间,就达不到我们的初衷了。首先,你需要根据自己的具体工作环境,选择或者制定适合自己公司或团队的编码规范。市面上可以参考的规范,也就是在文章开头提到的 PEP8 和 Google Style。
要知道,没有放之四海而皆准的规范,我们必须要因地制宜。例如在 Google 中,因为历史原因 C++ 不使用异常,引入异常对整个代码库带来的风险已经远大于它的益处,所以在它的 C++ 代码规范中,禁止使用异常。
一旦确定了整个团队所遵从的编码规范,就一定要强制执行,有什么好的办法呢?靠强制代码评审和强制静态或者动态 linter。具体流程是:
- 在代码评审工具里,添加必须的编码规范环节;
- 把团队确定的代码规范写进 Pylint 里,能够在每份代码提交前自动检查,不通过的代码无法提交。
整合之后,你的团队工作流程就会变成图 1 所示的这样。
图 1 自动检查编码规范的工作流程
学到这里,相信你对代码风格的重要性有了全新的认识。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算