逻辑结构和存储结构有什么区别?
逻辑结构是数据元素之间的关系,存储结构是数据元素及其关系在计算机中的存储方式。例如,小明和小勇是表兄弟,这是他们之间的逻辑关系;他们在教室里面的位置是他们的存储结构。无论他们的座位怎样安排,是挨着坐,还是分开坐,都不影响他们的表兄弟关系。
数据结构的逻辑结构共有以下4种。
集合中的元素是离散、无序的,就像鸡圈中的小鸡一样,可以随意走动,它们之间没有什么关系,唯一的亲密关系就是在同一个鸡圈里,如图1所示。
数据结构重点研究的是数据之间的关系,而集合中的元素是离散的,没有什么关系。因此,集合虽然是一种数据结构,但在很多数据结构教材中都不讲,而在离散数学的集合论部分有重点讲述。

图1:集合示意图
线性结构就像穿珠子,是一条线,不会分叉,如图2所示。有唯一的开始和唯一的结束,除了第一个元素外,每个元素都有唯一的直接前驱(前面那个);除了最后一个元素外,每个元素都有唯一的直接后继(后面那个)。
 :
:
图2:线性结构
树形结构就像一棵倒立的树,树根可以发出多个分支,每个每支也可以继续发出分支,树枝和树枝之间是不相交的,如图3所示。
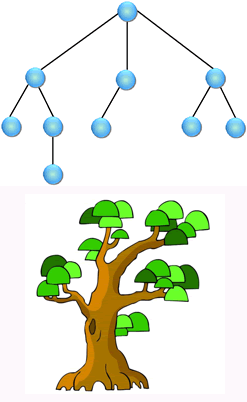
图3:树形结构
图形结构就像我们经常见到的地图,任何一个节点都可能和其他节点有关系,就像一张错综复杂的网,如图4所示。
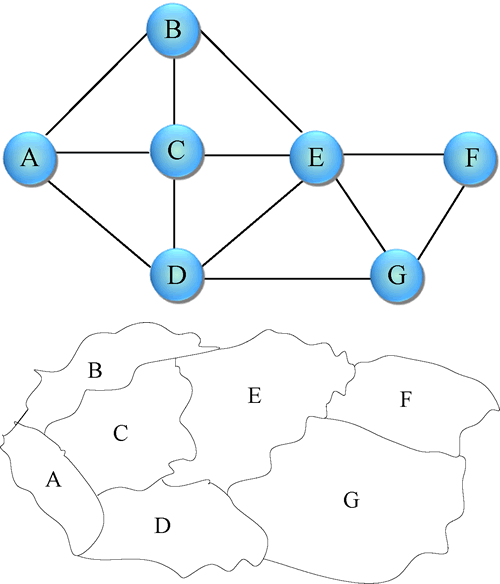
图4:图形结构
存储结构可以分为4种:顺序存储、链式存储、散列存储和索引存储。很多数据结构类教材只介绍了前两种基本的存储结构,这里加上后两种,以便读者了解。
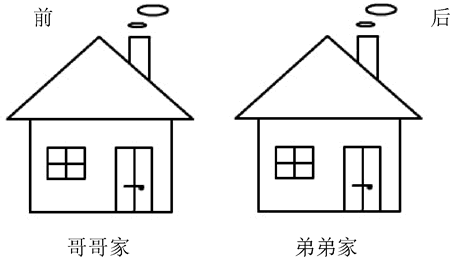
图5:兄弟两家前后相邻
顺序存储采用一段连续的存储空间,将逻辑上相邻的元素存储在连续的空间内,中间不允许有空。顺序存储可以快速定位第几个元素的地址,但是插入和删除时需要移动大量元素,如图6所示。
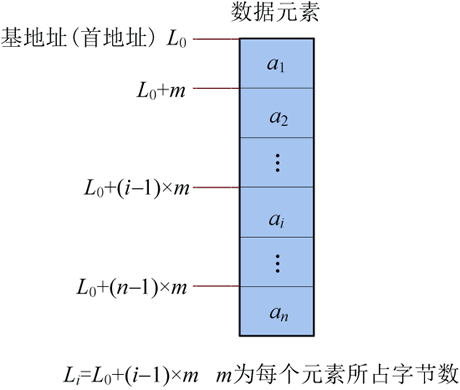
图6:顺序存储
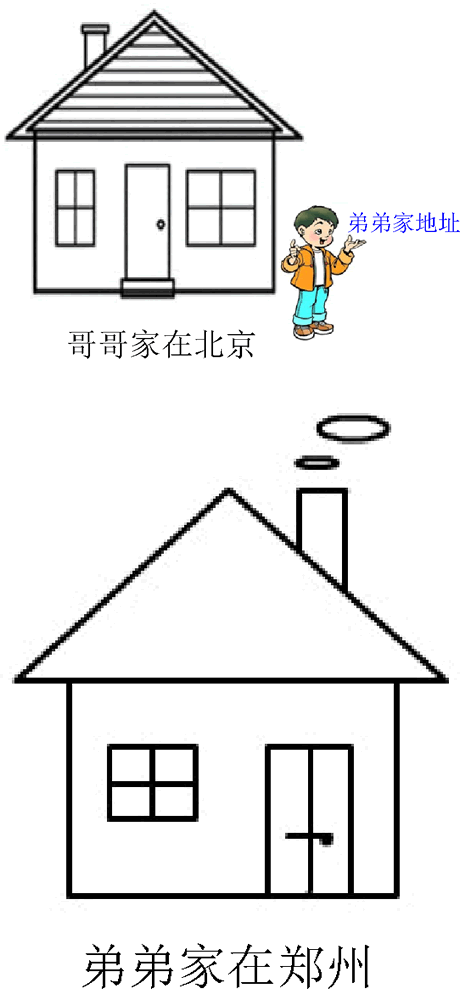
图7:哥哥有弟弟家地址
链式存储就像一个铁链子,一环扣一环才能连在一起。每个节点除了数据域,还有一个指针域,记录下一个元素的存储地址,如图8所示。

图8:链式存储
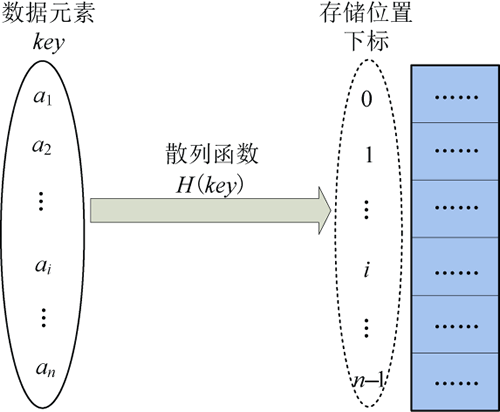
图9:散列存储
例如,假设散列表的地址范围为 0~9,散列函数为 H(key)=key%10,输入关键码序列(24,10,32,17,41,15,49):
构造散列表,如图10所示。

图10:散列表
散列存储可以通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。如果有冲突,则有多种处理冲突的方法。
索引表由若干索引项组成。如果每个节点在索引表中都有一个索引项,则该索引表称为稠密索引。若一组节点在索引表中只对应于一个索引项,则该索引表称为稀疏索引。索引项的一般形式是关键字、地址,如图11所示。
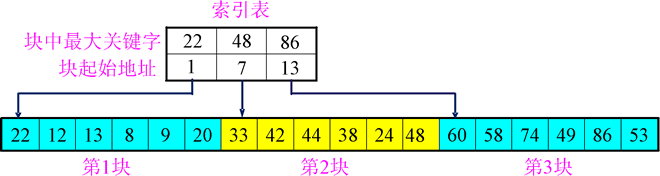
图11:索引存储
在搜索引擎中,需要按某些关键字的值来查找记录,为此可以按关键字建立索引,这种索引称为倒排索引。
为什么称为倒排索引呢?因为正常情况下,都是由记录来确定属性值的,而这里是根据属性值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。带有倒排索引的文件称为倒排索引文件,又称为倒排文件。倒排文件可以实现快速检索,索引存储是目前搜索引擎最常用的存储方法,如图12所示。
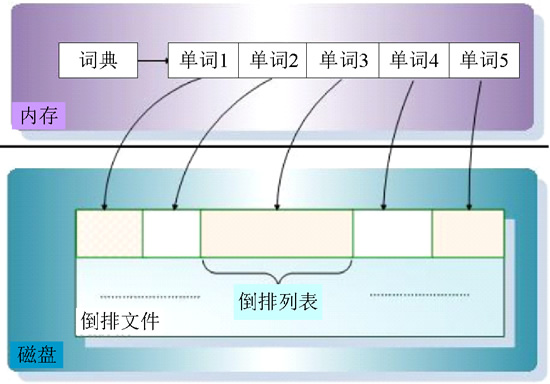
图12:倒排索引
逻辑结构
逻辑结构是指数据元素间抽象化的相互关系,与数据的存储无关,独立于计算机,它是从具体问题中抽象出来的数学模型。数据结构的逻辑结构共有以下4种。
1) 集合
数据元素间除“同属于一个集合”外,无其他关系。集合中的元素是离散、无序的,就像鸡圈中的小鸡一样,可以随意走动,它们之间没有什么关系,唯一的亲密关系就是在同一个鸡圈里,如图1所示。
数据结构重点研究的是数据之间的关系,而集合中的元素是离散的,没有什么关系。因此,集合虽然是一种数据结构,但在很多数据结构教材中都不讲,而在离散数学的集合论部分有重点讲述。
图1:集合示意图
2) 线性结构
一个对一个,如线性表、栈、队列、数组、广义表。线性结构就像穿珠子,是一条线,不会分叉,如图2所示。有唯一的开始和唯一的结束,除了第一个元素外,每个元素都有唯一的直接前驱(前面那个);除了最后一个元素外,每个元素都有唯一的直接后继(后面那个)。
:图2:线性结构
3) 树形结构
一个对多个,像树一样。树形结构就像一棵倒立的树,树根可以发出多个分支,每个每支也可以继续发出分支,树枝和树枝之间是不相交的,如图3所示。
图3:树形结构
4) 图形结构
多个对多个,如图、网。图形结构就像我们经常见到的地图,任何一个节点都可能和其他节点有关系,就像一张错综复杂的网,如图4所示。
图4:图形结构
存储结构
存储结构指的是数据元素及其关系在计算机中的存储方式。存储结构可以分为4种:顺序存储、链式存储、散列存储和索引存储。很多数据结构类教材只介绍了前两种基本的存储结构,这里加上后两种,以便读者了解。
1) 顺序存储
顺序存储是指逻辑上相邻的元素在计算机内的存储位置也是相邻的。例如,张小明是哥哥,张小波是弟弟,他们的逻辑关系是兄弟,如果他们住的房子是前后院,也是相邻的,就可以说他们是顺序存储,如图5所示。图5:兄弟两家前后相邻
顺序存储采用一段连续的存储空间,将逻辑上相邻的元素存储在连续的空间内,中间不允许有空。顺序存储可以快速定位第几个元素的地址,但是插入和删除时需要移动大量元素,如图6所示。
图6:顺序存储
2) 链式存储
链式存储是指逻辑上相邻的元素在计算机内的存储位置不一定是相邻的。例如,哥哥张小明因为工作调动去了北京,弟弟仍然在郑州,他们的位置是不相邻的,但是哥哥有弟弟家的地址,很容易可以找到弟弟,就可以说他们是链式存储,如图7所示。图7:哥哥有弟弟家地址
链式存储就像一个铁链子,一环扣一环才能连在一起。每个节点除了数据域,还有一个指针域,记录下一个元素的存储地址,如图8所示。
图8:链式存储
3) 散列存储
散列存储,又称哈希(Hash)存储,由节点的关键码值决定节点的存储地址。用散列函数确定数据元素的存储位置与关键码之间的对应关系,如图9所示。图9:散列存储
例如,假设散列表的地址范围为 0~9,散列函数为 H(key)=key%10,输入关键码序列(24,10,32,17,41,15,49):
- 24%10=4:存储在下标为4的位置;
- 10%10=0:存储在下标为0的位置;
- 32%10=2:存储在下标为2的位置;
- 17%10=7:存储在下标为7的位置;
- 41%10=1:存储在下标为1的位置;
- 15%10=5:存储在下标为5的位置;
- 49%10=9:存储在下标为9的位置。
构造散列表,如图10所示。
图10:散列表
散列存储可以通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。如果有冲突,则有多种处理冲突的方法。
4) 索引存储
索引存储是指除建立存储节点信息外,还建立附加的索引表来标识节点的地址。索引表由若干索引项组成。如果每个节点在索引表中都有一个索引项,则该索引表称为稠密索引。若一组节点在索引表中只对应于一个索引项,则该索引表称为稀疏索引。索引项的一般形式是关键字、地址,如图11所示。
图11:索引存储
在搜索引擎中,需要按某些关键字的值来查找记录,为此可以按关键字建立索引,这种索引称为倒排索引。
为什么称为倒排索引呢?因为正常情况下,都是由记录来确定属性值的,而这里是根据属性值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。带有倒排索引的文件称为倒排索引文件,又称为倒排文件。倒排文件可以实现快速检索,索引存储是目前搜索引擎最常用的存储方法,如图12所示。
图12:倒排索引
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算