页表结构完全攻略
本节我们将探讨组织页表的一些最常用技术,包括分层分页、哈希页表和倒置页表。
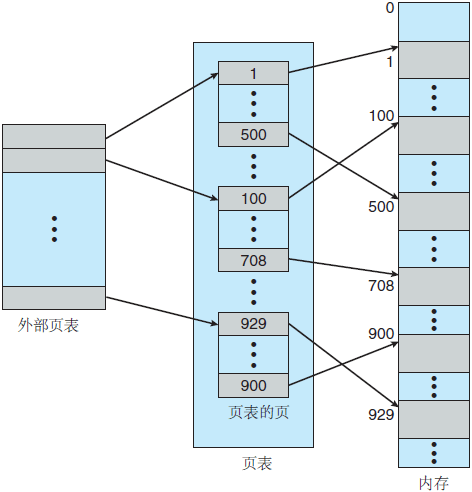
图 1 两级页表方案
一种方法是使用两层分页算法,就是将页表再分页(图 1)。例如,再次假设一个系统,具有 32 位逻辑地址空间和 4K 大小的页。一个逻辑地址被分为 20 位的页码和 12 位的页偏移。因为要对页表进行再分页,所以该页码可分为 10 位的页码和 10 位的页偏移。这样,一个逻辑地址就分为如下形式:
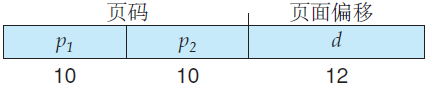
其中 ρ1 是用来访问外部页表的索引,而 ρ2 是内部页表的页偏移。采用这种结构的地址转换方法如图 2 所示。
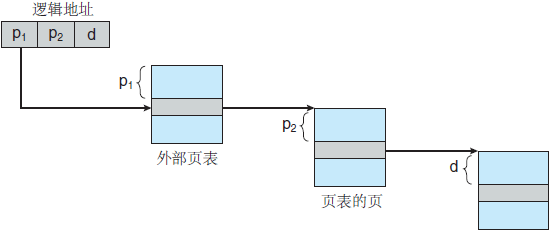
图 2 两级 32 位分页架构的地址转换
由于地址转换由外向内,这种方案也称为向前映射页表。
考虑一个经典系统 VAX 的内存管理。VAX 是数字设备公司的小型机。从 1977 年到 2000 年,VAX 是最受欢迎的小型机。VAX 架构支持两级分页的一种变体。
VAX 是一个 32 位的机器,它的页大小为 512 字节。进程的逻辑地址空间分为 4 个区,每个区为 230 字节。每个区表示一个进程的逻辑地址空间的不同部分。逻辑地址的头两个高位表示适当的区,接下来的 21 位表示区内的页码,最后的 9 位表示所需的页内偏移。
通过这种分页方式,操作系统可以仅当进程需要时才使用某些区。虚拟地址空间的有的区经常根本未使用,多层页表也没有这些空间的条目,进而大大减少了存储虚伪内存数据结构的所需内存。
VAX 架构的一个地址如下:

其中 s 表示区号,ρ 是页表的索引,而 d 是页内偏移。即使采用此方法,一个 VAX 进程如使用一个区,单层页表的大小为 221X4B = 8MB。为了进一步减少主存的使用,VAX 对用户进程的页表进行分页。
对于 64 位的逻辑地址空间的系统,两层分页方案就不再适合。为了说明这一点,假设系统的页面大小为 4KB(212)。这时,页表可由多达 252 个条目组成。如果采用两层分页,那么内部页表可方便地定为一页长,或包括 210 个 4 字节的条目。地址形式如下图所示:

外部页表有 242 个条目,或 244 字节。避免这样一个大页表的显而易见的方法是,将外部页表再进一步细分。(这种方法也可用于 32 位处理器,以增加灵活性和有效性。)
外部页表的划分有很多方法。例如,我们可以对外部页表再分页,进而得到三层分页方案。假设外部页表由标准大小的页组成(210 个条目或者 212 字节)。这时,64 位地址空间仍然很大:

外部页表的大小仍然为 234 字节(16GB)。
下一步是四层分页方案,这里第二级的外部页表本身也被分页,等等。为了转换每个逻辑地址,64 位的 UltraSPARC 将需要 7 个级别的分页,如此多的内存访问是不可取的。从这个例子可以看出,对于 64 位的架构,为什么分层页表通常被认为是不适当的。
该算法工作如下,虚拟地址的虚拟页码哈希到哈希表,用虚拟页码与链表内的第一个元素的第一个字段相比较,如果匹配,那么相应的帧码(第二个字段)就用来形成物理地址;反之,如果不匹配,那么与链表内的后续节点的第一个字段进行比较,以查找匹配的页码。
该方案如图 3 所示。
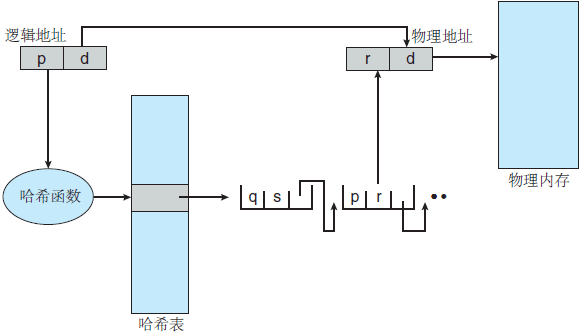
图 3 哈希页表
已提出用于 64 位地址空间的这个方案的一个变体。此变体采用聚簇页表,类似于哈希页表;不过,哈希表内的每个条目引用多个页(例如 16)不是单个页。因此,单个页表条目可以映射到多个物理帧。聚簇页表对于稀疏地址空间特别有用,这里的引用是不连续的并且散布在整个地址空间中。
由于页表是按虚拟地址排序的,操作系统可计算出所对应条目在页表中的位置,可以直接使用该值。这种方法的缺点之一是,每个页表可能包含数以百万计的条目。这些表可能需要大量的物理内存,以跟踪其他物理内存是如何使用的。
为了解决这个问题,我们可以使用倒置页表。对于每个真正的内存页或帧,倒置页表才有一个条目。每个条目包含保存在真正内存位置上的页的虚拟地址,以及拥有该页进程的信息。因此,整个系统只有一个页表,并且每个物理内存的页只有一条相应的条目。
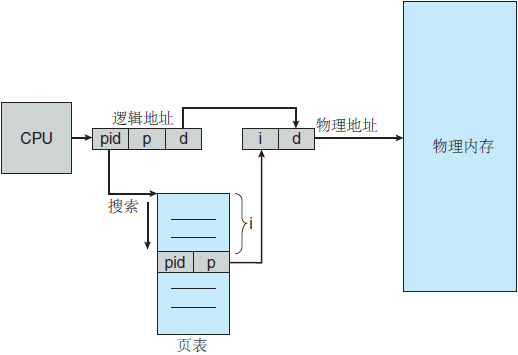
图 4 倒置页表
图 4 显示了倒置页表的工作原理,由于一个倒置页表通常包含多个不同的映射物理内存的地址空间,通常要求它的每个条目保存一个地址空间标识符。地址空间标识符的保存确保了,具体进程的每个逻辑页可映射到相应的物理帧。采用倒置页表的系统包括 64 位 UltraSPARC 和 PowerPC。
为了说明这种方法,这里描述一种用于 IBM RT 的倒置页表的简化版本。IBM 是最早采用倒置页表的大公司:从 IBM System 38、RS/6000,到现代的 IBM Power CPU。
对 IBM RT,系统内的每个虚拟地址为一个三元组:
虽然这种方案减少了存储每个页表所需的内存空间,但是它增加了由于引用页而查找页表所需的时间。由于倒置页表是按物理地址来排序的,而查找是根据虚拟地址的,因此查找匹配可能需要搜索整个表。这种搜索需要很长时间。
为了解决这个问题,可以使用一个哈希表,以将搜索限制在一个或最多数个页表条目。当然,每次访问哈希表也增加了一次内存引用,因此每次虚拟地址的引用至少需要两个内存读:一个用于哈希表条目,另一个用于页表。(记住:在搜索哈希表之前,先搜索 TLB,这可改善性能。)
采用倒置页表的系统在实现共享内存时会有困难。共享内存的通常实现为,将多个虚拟地址(共享内存的每个进程都有一个虚拟地址)映射到一个物理地址。这种标准的方法不能用于倒置页表,因为每个物理页只有一个虚拟页条目,一个物理页不可能有两个(或多个)共享的虚拟地址。
解决这个问题的一个简单技术是,只允许页表包含一个虚拟地址到共享物理地址的映射。这意味着,对未映射的虚拟地址的引用会导致页错误。
它有两个哈希表:一个用于内核,一个用于所有用户进程。每个将虚拟内存的内存地址映射到物理内存。每个哈希表条目代表一个已映射的、连续的、虚拟内存区域;比每个条目仅代表一页,更为有效。每个条目都有一个基地址和一个表示页数多少的跨度。
如果每个地址都要搜索哈希表,那么虚拟到物理的转换时间会太长;因此 CPU 有一个 TLB,它用于保存转换表条目(TTE),以便进行快速硬件查找。这些 TTE 缓存驻留在一个转换存储缓冲区(TSB),其中包括最近访问页的有关条目。当引用一个虚拟地址时,硬件搜索 TLB 以进行转换。如果没有找到,硬件搜索内存中的 TSB,以查找对应于导致查找虚拟地址的 TTE。
这种 TLB 查找功能常见于现代 CPU。如果 TSB 中找到了匹配,CPU 将 TSB 条目复制到 TLB,进而完成内存转换。如果 TSB 中未找到匹配,则中断内核,以搜索哈希表。然后,内核从相应的哈希表中创建一个 TTE,并保存到 TSB 中;而 CPU 内存管理单元会通过 TSB 自动加载 TLB。最后,中断处理程序将控制返回到 MMU,完成地址转换,获得内存中的字节或字。
分层分页
大多数现代计算机系统支持大逻辑地址空间(232〜264)。在这种情况下,页表本身可以非常大。例如,假设具有 32 位逻辑地址空间的一个计算机系统。如果系统的页大小为 4KB(212),那么页表可以多达 100 万的条目(232/212)。假设每个条目有 4 字节,那么每个进程需要 4MB 物理地址空间来存储页表本身。显然,我们并不想在内存中连续地分配这个页表。这个问题的一个简单解决方法是将页表划分为更小的块。完成这种划分有多个方法。图 1 两级页表方案
一种方法是使用两层分页算法,就是将页表再分页(图 1)。例如,再次假设一个系统,具有 32 位逻辑地址空间和 4K 大小的页。一个逻辑地址被分为 20 位的页码和 12 位的页偏移。因为要对页表进行再分页,所以该页码可分为 10 位的页码和 10 位的页偏移。这样,一个逻辑地址就分为如下形式:
图 2 两级 32 位分页架构的地址转换
由于地址转换由外向内,这种方案也称为向前映射页表。
考虑一个经典系统 VAX 的内存管理。VAX 是数字设备公司的小型机。从 1977 年到 2000 年,VAX 是最受欢迎的小型机。VAX 架构支持两级分页的一种变体。
VAX 是一个 32 位的机器,它的页大小为 512 字节。进程的逻辑地址空间分为 4 个区,每个区为 230 字节。每个区表示一个进程的逻辑地址空间的不同部分。逻辑地址的头两个高位表示适当的区,接下来的 21 位表示区内的页码,最后的 9 位表示所需的页内偏移。
通过这种分页方式,操作系统可以仅当进程需要时才使用某些区。虚拟地址空间的有的区经常根本未使用,多层页表也没有这些空间的条目,进而大大减少了存储虚伪内存数据结构的所需内存。
VAX 架构的一个地址如下:
其中 s 表示区号,ρ 是页表的索引,而 d 是页内偏移。即使采用此方法,一个 VAX 进程如使用一个区,单层页表的大小为 221X4B = 8MB。为了进一步减少主存的使用,VAX 对用户进程的页表进行分页。
对于 64 位的逻辑地址空间的系统,两层分页方案就不再适合。为了说明这一点,假设系统的页面大小为 4KB(212)。这时,页表可由多达 252 个条目组成。如果采用两层分页,那么内部页表可方便地定为一页长,或包括 210 个 4 字节的条目。地址形式如下图所示:
外部页表有 242 个条目,或 244 字节。避免这样一个大页表的显而易见的方法是,将外部页表再进一步细分。(这种方法也可用于 32 位处理器,以增加灵活性和有效性。)
外部页表的划分有很多方法。例如,我们可以对外部页表再分页,进而得到三层分页方案。假设外部页表由标准大小的页组成(210 个条目或者 212 字节)。这时,64 位地址空间仍然很大:
外部页表的大小仍然为 234 字节(16GB)。
下一步是四层分页方案,这里第二级的外部页表本身也被分页,等等。为了转换每个逻辑地址,64 位的 UltraSPARC 将需要 7 个级别的分页,如此多的内存访问是不可取的。从这个例子可以看出,对于 64 位的架构,为什么分层页表通常被认为是不适当的。
哈希页表
处理大于 32 位地址空间的常用方法是使用哈希页表,采用虚拟页码作为哈希值。哈希页表的每一个条目都包括一个链表,该链表的元素哈希到同一位置(该链表用来解决处理碰撞)。每个元素由三个字段组成:虚拟页码,映射的帧码,指向链表内下一个元素的指针。该算法工作如下,虚拟地址的虚拟页码哈希到哈希表,用虚拟页码与链表内的第一个元素的第一个字段相比较,如果匹配,那么相应的帧码(第二个字段)就用来形成物理地址;反之,如果不匹配,那么与链表内的后续节点的第一个字段进行比较,以查找匹配的页码。
该方案如图 3 所示。
图 3 哈希页表
已提出用于 64 位地址空间的这个方案的一个变体。此变体采用聚簇页表,类似于哈希页表;不过,哈希表内的每个条目引用多个页(例如 16)不是单个页。因此,单个页表条目可以映射到多个物理帧。聚簇页表对于稀疏地址空间特别有用,这里的引用是不连续的并且散布在整个地址空间中。
倒置页表
通常,每个进程都有一个关联的页表。该进程所使用的每个页都在页表中有一项(或者每个虚拟页都有一项,不管后者是否有效)。这种表示方式比较自然,因为进程是通过虚拟地址来引用页的。操作系统应将这种引用转换成物理内存的地址。由于页表是按虚拟地址排序的,操作系统可计算出所对应条目在页表中的位置,可以直接使用该值。这种方法的缺点之一是,每个页表可能包含数以百万计的条目。这些表可能需要大量的物理内存,以跟踪其他物理内存是如何使用的。
为了解决这个问题,我们可以使用倒置页表。对于每个真正的内存页或帧,倒置页表才有一个条目。每个条目包含保存在真正内存位置上的页的虚拟地址,以及拥有该页进程的信息。因此,整个系统只有一个页表,并且每个物理内存的页只有一条相应的条目。
图 4 倒置页表
图 4 显示了倒置页表的工作原理,由于一个倒置页表通常包含多个不同的映射物理内存的地址空间,通常要求它的每个条目保存一个地址空间标识符。地址空间标识符的保存确保了,具体进程的每个逻辑页可映射到相应的物理帧。采用倒置页表的系统包括 64 位 UltraSPARC 和 PowerPC。
为了说明这种方法,这里描述一种用于 IBM RT 的倒置页表的简化版本。IBM 是最早采用倒置页表的大公司:从 IBM System 38、RS/6000,到现代的 IBM Power CPU。
对 IBM RT,系统内的每个虚拟地址为一个三元组:
〈进程id,页码,偏移〉
每个倒置页表条目为二元组〈进程 id,页码〉,这里进程 id 用来作为地址空间的标识符。当发生内存引用时,由〈进程 id,页码〉组成的虚拟地址被提交到内存子系统。然后,搜索倒置页表来寻找匹配。如果找到匹配条目,如条目 i,则生成物理地址〈i,偏移〉。如果找不到匹配,则为非法地址访问。虽然这种方案减少了存储每个页表所需的内存空间,但是它增加了由于引用页而查找页表所需的时间。由于倒置页表是按物理地址来排序的,而查找是根据虚拟地址的,因此查找匹配可能需要搜索整个表。这种搜索需要很长时间。
为了解决这个问题,可以使用一个哈希表,以将搜索限制在一个或最多数个页表条目。当然,每次访问哈希表也增加了一次内存引用,因此每次虚拟地址的引用至少需要两个内存读:一个用于哈希表条目,另一个用于页表。(记住:在搜索哈希表之前,先搜索 TLB,这可改善性能。)
采用倒置页表的系统在实现共享内存时会有困难。共享内存的通常实现为,将多个虚拟地址(共享内存的每个进程都有一个虚拟地址)映射到一个物理地址。这种标准的方法不能用于倒置页表,因为每个物理页只有一个虚拟页条目,一个物理页不可能有两个(或多个)共享的虚拟地址。
解决这个问题的一个简单技术是,只允许页表包含一个虚拟地址到共享物理地址的映射。这意味着,对未映射的虚拟地址的引用会导致页错误。
Oracle SPARC Solaris
以一个现代的 64 位 CPU 和与其紧密集成并提供低开销虚拟内存的操作系统为例,来进行分析。Solaris 运行于 SPARC 处理器上,是一个真正 64 位的操作系统;它需要通过多级页表来提供虚拟内存且不会用完所有物理内存。它的做法有点复杂,但通过哈希表有效地解决了问题。它有两个哈希表:一个用于内核,一个用于所有用户进程。每个将虚拟内存的内存地址映射到物理内存。每个哈希表条目代表一个已映射的、连续的、虚拟内存区域;比每个条目仅代表一页,更为有效。每个条目都有一个基地址和一个表示页数多少的跨度。
如果每个地址都要搜索哈希表,那么虚拟到物理的转换时间会太长;因此 CPU 有一个 TLB,它用于保存转换表条目(TTE),以便进行快速硬件查找。这些 TTE 缓存驻留在一个转换存储缓冲区(TSB),其中包括最近访问页的有关条目。当引用一个虚拟地址时,硬件搜索 TLB 以进行转换。如果没有找到,硬件搜索内存中的 TSB,以查找对应于导致查找虚拟地址的 TTE。
这种 TLB 查找功能常见于现代 CPU。如果 TSB 中找到了匹配,CPU 将 TSB 条目复制到 TLB,进而完成内存转换。如果 TSB 中未找到匹配,则中断内核,以搜索哈希表。然后,内核从相应的哈希表中创建一个 TTE,并保存到 TSB 中;而 CPU 内存管理单元会通过 TSB 自动加载 TLB。最后,中断处理程序将控制返回到 MMU,完成地址转换,获得内存中的字节或字。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算