首页 > 编程笔记 > JavaScript笔记
JS charAt()、charCodeAt()和fromCharCode():字符查找
JavaScript charAt()、charCodeAt() 和 fromCharCode() 3 个方法都是针对字符的操作。charAt() 是按位置返回字符;charCodeAt() 是按位置返回对应字符的 Unicode 编码;fromCharCode() 则是根据字符的 Unicode 编码返回对应的字符。
charAt() 返回 str 字符串中指定位置的单个字符。之前我们介绍了字符在字符串中的位置使用索引来表示,字符索引的取值从 0 开始依次递增。该方法需要通过字符串来调用,使用示例如下:

图 1:获取字符串指定位置的字符
从图 1 可见,字符串变量和字符串对象都可调用 charAt(),且结果完全一样。
charCodeAt() 返回 str 字符串指定位置处字符的 Unicode 编码,Unicode 编码取值范围为 0~1114111,其中前 128 个 Unicode 编码和 ASCII 字符编码一样。需要注意的是,如果指定的位置索引值小于 0 或大于字符串的长度,则 charCodeAt() 将返回 NaN。
charCodeAt() 的使用示例如下:

图 2:获取字符串指定位置的字符
fromCharCode() 是静态方法,需要通过 String 来调用,所以应该写作 String.fromCharCode(),其中的参数可以包含 1 到多个 Unicode 编码,按参数顺序返回对应的字符。
from CharCode() 的使用示例如下:
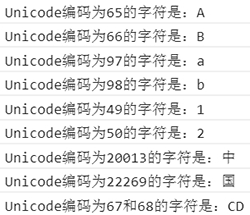
图 3:根据 Unicode 编码获取字符
从图 3 可看出,最后一行代码包含 67 和 68 两个 Unicode 编码参数,其结果按参数的顺序分别返回 C 和 D 两个字符。
charCodeAt() 和 fromCharCode() 两个方法在实际应用中常用来对普通级别的文本内容进行加密和解密,具体代码请见例 1。
【例 1】使用 charCodeAt() 和 fromCharCode() 对文本内容加密和解密。
例 1 在 Chrome 浏览器中运行结果如图 4、图 5 和图 6 所示。
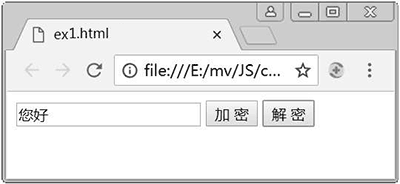
图 4:输入的明文
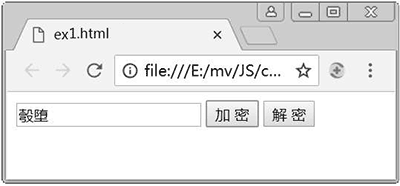
图 5:加密后得到的密文
图 6:解密后得到的明文
1. charAt() 方法
charAt() 的用法为:str.charAt(index)
对象/参数说明:- str 为被检索的字符串对象;
- index 为字符的下标。
charAt() 返回 str 字符串中指定位置的单个字符。之前我们介绍了字符在字符串中的位置使用索引来表示,字符索引的取值从 0 开始依次递增。该方法需要通过字符串来调用,使用示例如下:
var str = "欢迎学习JavaScript";
var oStr = new String("欢迎学习JavaScript");
console.log("字符串变量str的第1个字符是:'"+str.charAt(0)+"'");
console.log("字符串变量str的第2个字符是:'"+str.charAt(1)+"'");
console.log("字符串变量str的第5个字符是:'"+str.charAt(4)+"'");
console.log("字符串对象oStr的第1个字符是:'"+oStr.charAt(0)+"'");
console.log("字符串对象oStr的第2个字符是:'"+oStr.charAt(1)+"'");
console.log("字符串对象oStr的第5个字符是:'"+oStr.charAt(4)+"'");
上述代码在 Chrome 浏览器的控制台中运行后的结果如图 1 所示。
图 1:获取字符串指定位置的字符
从图 1 可见,字符串变量和字符串对象都可调用 charAt(),且结果完全一样。
2. charCodeAt() 方法
charCodeAt() 的用法为:str.charCodeAt(index)
str 和 index 的含义与 charAt() 方法相同,此处不再赘述。charCodeAt() 返回 str 字符串指定位置处字符的 Unicode 编码,Unicode 编码取值范围为 0~1114111,其中前 128 个 Unicode 编码和 ASCII 字符编码一样。需要注意的是,如果指定的位置索引值小于 0 或大于字符串的长度,则 charCodeAt() 将返回 NaN。
charCodeAt() 的使用示例如下:
var str1 = "AB";
var str2 = "ab";
var str3 = "12";
var str4 = "中国";
console.log("'AB'字符串的第1个字符的Unicode编码为:"+str1.charCodeAt(0));
console.log("'AB'字符串的第2个字符的Unicode编码为:"+str1.charCodeAt(1));
console.log("'ab'字符串的第1个字符的Unicode编码为:"+str2.charCodeAt(0));
console.log("'ab'字符串的第2个字符的Unicode编码为:"+str2.charCodeAt(1));
console.log("'12'字符串的第1个字符的Unicode编码为:"+str3.charCodeAt(0));
console.log("'12'字符串的第2个字符的Unicode编码为:"+str3.charCodeAt(1));
console.log("'中国'字符串的第1个字符的Unicode编码为:"+str4.charCodeAt(0));
console.log("'中国'字符串的第2个字符的Unicode编码为:"+str4.charCodeAt(1));
上述代码在 Chrome 浏览器的控制台中运行后的结果如图 2 所示。
图 2:获取字符串指定位置的字符
3. fromCharCode() 方法
fromCharCode() 的用法为:String.fromCharCode( Unicode1, …, UnicodeN )
Unicode1, …, UnicodeN 表示字符的 Unicode 编码。fromCharCode() 是静态方法,需要通过 String 来调用,所以应该写作 String.fromCharCode(),其中的参数可以包含 1 到多个 Unicode 编码,按参数顺序返回对应的字符。
from CharCode() 的使用示例如下:
console.log("Unicode编码为65的字符是:"+String.fromCharCode(65));
console.log("Unicode编码为66的字符是:"+String.fromCharCode(66));
console.log("Unicode编码为97的字符是:"+String.fromCharCode(97));
console.log("Unicode编码为98的字符是:"+String.fromCharCode(98));
console.log("Unicode编码为49的字符是:"+String.fromCharCode(49));
console.log("Unicode编码为50的字符是:"+String.fromCharCode(50));
console.log("Unicode编码为20013的字符是:"+String.fromCharCode(20013));
console.log("Unicode编码为22269的字符是:"+String.fromCharCode(22269));
console.log("Unicode编码为67和68的字符是:"+String.fromCharCode(67,68));
上述代码在 Chrome 浏览器的控制台中运行后的结果如图 3 所示。
图 3:根据 Unicode 编码获取字符
从图 3 可看出,最后一行代码包含 67 和 68 两个 Unicode 编码参数,其结果按参数的顺序分别返回 C 和 D 两个字符。
charCodeAt() 和 fromCharCode() 两个方法在实际应用中常用来对普通级别的文本内容进行加密和解密,具体代码请见例 1。
【例 1】使用 charCodeAt() 和 fromCharCode() 对文本内容加密和解密。
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>ex1.html</title>
<script>
window.onload = function(){
var aInp = document.getElementsByTagName('input');
var str = null;
//var n1 = 360;
aInp[1].onclick = function(){
encodeDecode(-360);
};
aInp[2].onclick = function(){
encodeDecode(360);
};
function encodeDecode(num){
str = aInp[0].value;
var str1 = '';
for(var i = 0; i < str.length; i++){
//num为负值时加密,为正值时解密
str1 += String.fromCharCode(str.charCodeAt(i)+num);
}
aInp[0].value = str1;
}
};
</script>
</head>
<body>
<input type="text"/>
<input type="button" value="加 密"/>
<input type="button" value="解 密"/>
</body>
</html>
上述代码的功能是对文本框中输入的文本内容进行加密和解密。加密时首先获取到文本框中输入的内容(即明文),然后使用 charCodeAt() 获取明文中每个字符的 Unicode 编码值,该值减 360 后再通过 fromCharCode() 获取对应的字符,得到的字符即为密文。解密和加密类似,不同在于其首先获取的是密文,且对密文中的每个字符的 Unicode 编码加 360,最后得到的字符即为明文。例 1 在 Chrome 浏览器中运行结果如图 4、图 5 和图 6 所示。
图 4:输入的明文
图 5:加密后得到的密文
图 6:解密后得到的明文
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算