Go语言封装qsort快速排序函数
快速排序(Quick Sort)是由“东尼·霍尔”所设计的一种排序算法。在平均状况下,排序 n 个项目要
事实上,快速排序通常明显比其他
qsort 快速排序函数是C语言中的一个高阶函数,支持用于自定义排序比较函数,可以对任意类型的数组进行排序。
本节我们为大家简单的介绍一下C语言中的 qsort 函数,并使用Go语言实现类似功能的 qsort 函数。
cmp 排序函数的两个指针参数分别是要比较的两个元素的地址,如果第一个参数对应的元素大于第二个参数对应的元素则返回结果大于 0,如果两个元素相等则返回 0,如果第一个元素小于第二个元素则返回结果小于 0。
下面的代码展示了使用C语言的 qsort 函数对一个 int 类型的数组进行排序:
算法稳定性可以这样理解,假设在数列中存在
这句话很好理解:假设被排序的数列中有 N 个数,遍历一次的时间复杂度是
示例代码如下:
因此分治法的执行步骤为:
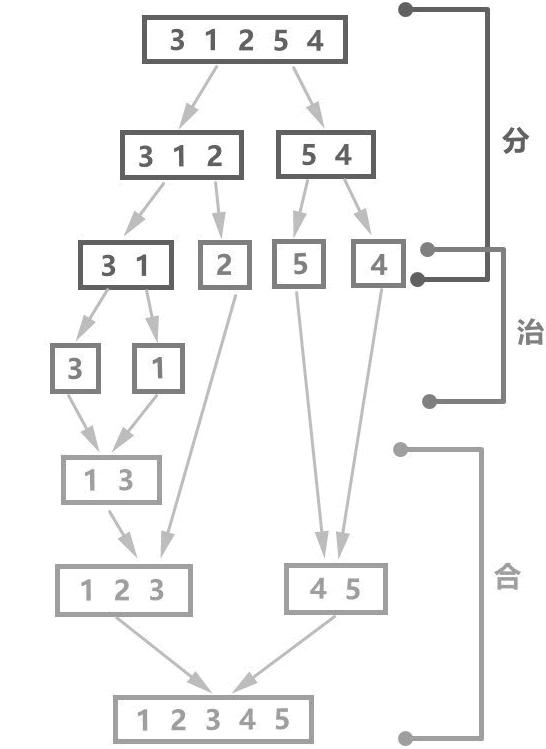
图:有序子序列两两归并形成新的有序序列
Ο(n log n) 次比较,在最坏状况下则需要Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他
Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来,且在大部分真实世界的数据,可以决定设计的选择,减少所需时间的二次方项之可能性。qsort 快速排序函数是C语言中的一个高阶函数,支持用于自定义排序比较函数,可以对任意类型的数组进行排序。
本节我们为大家简单的介绍一下C语言中的 qsort 函数,并使用Go语言实现类似功能的 qsort 函数。
认识 qsort 函数
qsort 快速排序函数有<stdlib.h> 标准库提供,函数的声明如下:
void qsort(
void* base, size_t num, size_t size,
int (*cmp)(const void*, const void*)
);
- base:参数是要排序数组的首个元素的地址;
- num:是数组中元素的个数;
- size:是数组中每个元素的大小;
- cmp:用于对数组中任意两个元素进行排序。
cmp 排序函数的两个指针参数分别是要比较的两个元素的地址,如果第一个参数对应的元素大于第二个参数对应的元素则返回结果大于 0,如果两个元素相等则返回 0,如果第一个元素小于第二个元素则返回结果小于 0。
下面的代码展示了使用C语言的 qsort 函数对一个 int 类型的数组进行排序:
#include <stdio.h>
#include <stdlib.h>
#define DIM(x) (sizeof(x)/sizeof((x)[0]))
static int cmp(const void* a, const void* b) {
const int* pa = (int*)a;
const int* pb = (int*)b;
return *pa - *pb;
}
int main() {
int values[] = { 42, 8, 109, 97, 23, 25 };
int i;
qsort(values, DIM(values), sizeof(values[0]), cmp);
for(i = 0; i < DIM(values); i++) {
printf ("%d ",values[i]);
}
return 0;
}
代码说明如下:
- DIM(values) 宏用于计算数组元素的个数;
- sizeof(values[0]) 用于计算数组元素的大小;
- cmp 是用于排序时比较两个元素大小的回调函数。
使用Go语言实现快速排序函数
1) 快速排序稳定性
快速排序是不稳定的算法,它不满足稳定算法的定义。算法稳定性可以这样理解,假设在数列中存在
a[i]=a[j],若在排序之前,a[i] 在 a[j] 前面,并且在排序之后,a[i] 仍然在 a[j] 前面,则这个排序算法才算是稳定的。2) 快速排序时间复杂度
快速排序的时间复杂度在最坏情况下是O(N²),平均的时间复杂度是O(N*lgN)。这句话很好理解:假设被排序的数列中有 N 个数,遍历一次的时间复杂度是
O(N),需要遍历多少次呢?至少lg(N+1) 次,最多 N 次。为什么最少是 lg(N+1) 次?
快速排序是采用的分治法进行遍历的,我们将它看作一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。因此,快速排序的遍历次数最少是lg(N+1) 次。为什么最多是 N 次?
将快速排序看作一棵二叉树,它的深度最大是 N,因此,快读排序的遍历次数最多是 N 次。示例代码如下:
package main
import (
"fmt"
)
func main() {
Arr := []int{23, 65, 13, 27, 42, 15, 38, 21, 4, 10}
qsort(Arr, 0, len(Arr)-1)
fmt.Println(Arr)
}
/**
快速排序:分治法+递归实现
随意取一个值A,将比A大的放在A的右边,比A小的放在A的左边;然后在左边的值AA中再取一个值B,将AA中比B小的值放在B的左边,将比B大的值放在B的右边。以此类推
*/
func qsort(arr []int, first, last int) {
flag := first
left := first
right := last
if first >= last {
return
}
// 将大于arr[flag]的都放在右边,小于的,都放在左边
for first < last {
// 如果flag从左边开始,那么是必须先从有右边开始比较,也就是先在右边找比flag小的
for first < last {
if arr[last] >= arr[flag] {
last--
continue
}
// 交换数据
arr[last], arr[flag] = arr[flag], arr[last]
flag = last
break
}
for first < last {
if arr[first] <= arr[flag] {
first++
continue
}
arr[first], arr[flag] = arr[flag], arr[first]
flag = first
break
}
}
qsort(arr, left, flag-1)
qsort(arr, flag+1, right)
}
运行结果如下:
[4 10 13 15 21 23 27 38 42 65]
分治法策略
快速排序使用分治法策略,分治法就是把一个复杂的问题分解成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到最后子问题可以简单的直接求解 (各个击破),原问题的解即子问题的解的合并。因此分治法的执行步骤为:
- 第一步(分):将原来复杂的问题分解为若干个规模较小、相互独立、与原问题形式相同的子问题,分解到可以直接求解为止;
- 第二步(治):此时可以直接求解;
- 第三步(合):将小规模的问题的解合并为一个更大规模的问题的解,自底向上逐步求出原来问题的解,如下图所示。
图:有序子序列两两归并形成新的有序序列
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算