内存分页机制完全攻略
分段允许进程的物理地址空间是非连续的。分页是提供这种优势的另一种内存管理方案。然而,分页避免了外部碎片和紧缩,而分段不可以。
不仅如此,分页还避免了将不同大小的内存块匹配到交换空间的问题,在分页引入之前采用的内存管理方案都有这个问题。由于比早期方法更加优越,各种形式的分页为大多数操作系统采用,包括大型机的和智能手机的操作系统。实现分页需要操作系统和计算机硬件的协作。
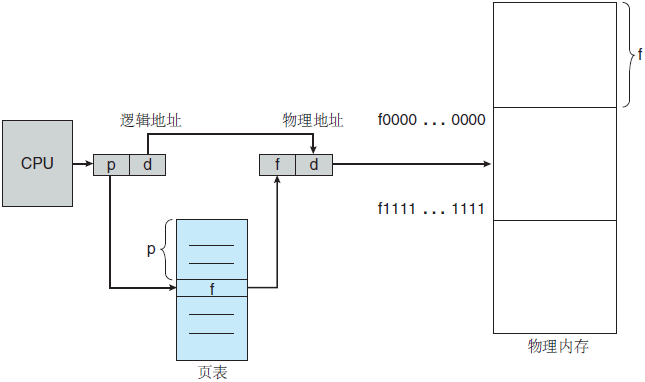
图 1 分页的硬件支持
分页的硬件支持如图 1 所示。由 CPU 生成的每个地址分为两部分:页码和页偏移。页码作为页表的索引。页表包含每页所在物理内存的基地址。这个基地址与页偏移的组合就形成了物理内存地址,可发送到物理单元。内存的分页模型如图 2 所示。
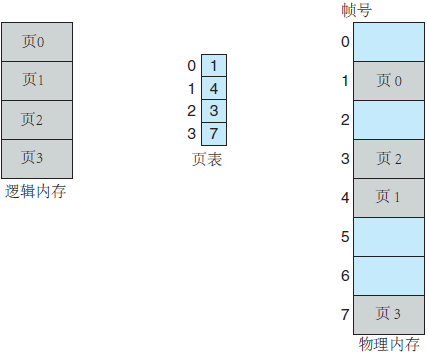
图 2 逻辑内存和物理内存的分页模型
页大小(与帧大小一样)是由硬件来决定的。页的大小为 2 的幂;根据计算机体系结构的不同,页大小可从 512 字节到 1GB 不等。将页的大小选为 2 的幂可以方便地将逻辑地址转换为页码和页偏移。如果逻辑地址空间为 2m,且页大小为 2n 字节,那么逻辑地址的高 m-n 位表示页码,而低 n 位表示页偏移。这样,逻辑地址就如下图所示:
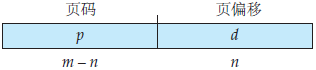
其中 p 作为页表的索引,而 d 作为页的偏移。
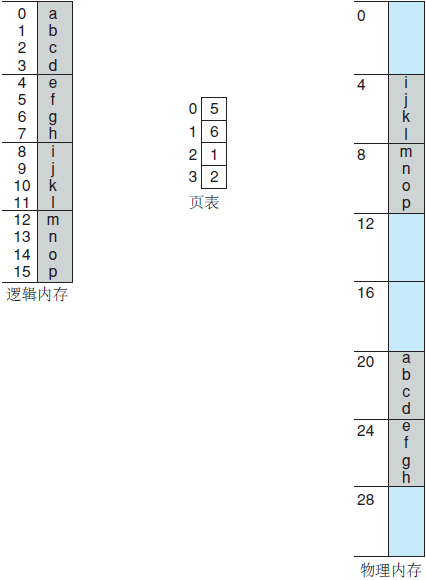
图 3 使用 4 字节的页对 32 字节的内存进行分页的例子
例如,假设如图 3 所示的内存。这里,逻辑的地址的 n 为 2,m 为 4。采用大小为 4 字节而物理内存为 32 字节(8 页),下面说明程序员的内存视图如何映射到物理内存。
逻辑地址 0 的页码为 0,页偏移为 0。根据页表,可以查到页码 0 对应帧 5,因此逻辑地址 0 映射到物理地址 20((5X4) + 0)。逻辑地址 3(页码为 0,页偏移为 3)映射到物理地址 23((5X4)+ 3)。逻辑地址 4 的页码为 1,页偏移为 0,根据页表,页码 1 对应为帧 6。因此,逻辑地址 4 映射到物理地址 24((6X4) + 0)。逻辑地址 13 映射到物理地址 9。
读者可能注意到,分页本身是一种动态的重定位。每个逻辑地址由分页硬件绑定为某个物理地址。采用分页类似于采用一组基址(重定位)寄存器,每个基址对应着一个内存帧。
采用分页方案不会产生外部碎片:每个空闲帧都可以分配给需要它的进程。不过,分页有内部碎片。注意,分配是以帧为单位进行的。如果进程所要求的内存并不是页的整数倍,那么最后一个帧就可能用不完。
例如,如果页的大小为 2048 字节,一个大小为 72 776 字节的进程需要 35 个页和 1086 字节。该进程会得到 36 个帧,因此有 2048-1086 = 962 字节的内部碎片。在最坏情况下,一个需要 n 页再加 1 字节的进程,需要分配 n + 1 个帧,这样几乎产生整个帧的内部碎片。
如果进程大小与页大小无关,那么每个进程的内部碎片的均值为半页。从这个角度来看,小的页面大小是可取的。不过,由于页表内的每项也有一定的开销,该开销随着页的增大而降低。再者,磁盘 I/O 操作随着传输量的增大也会更为有效。
一般来说,随着时间的推移,页的大小也随着进程、数据和内存的不断增大而增大。现在,页大小通常为 4KB〜8KB,有的系统可能支持更大的页。有的 CPU 和内核可能支持多种页大小。例如,Solaris 根据按页所存储的数据,可使用 8KB 或 4MB 的大小的页。研究人员正在研究,以便支持快速可变的页大小。
通常,对于 32 位的 CPU,每个页表条目是 4 字节长的,但是这个大小也可能改变。一个 32 位的条目可以指向 232 个物理帧中的任一个。如果帧为 4KB(212),那么具有 4 字节条目的系统可以访问 244字节大小(或 16TB)的物理内存。
这里我们应该注意到,分页内存系统的物理内存的大小不同于进程的最大逻辑大小。当进一步探索分页时,我们将引入其他的信息,这个信息应保存在页表条目中。该信息也减少了可用于帧地址的位数。因此,一个具有 32 位页表条目的系统可访问的物理内存可能小于最大值。32 位 CPU 采用 32 位地址,意味着,一个进程的空间只能为 232 字节(4GB)。因此,分页允许我们使用的物理内存大于 CPU 地址指针可访问的空间。
当系统进程需要执行时,它将检查该进程的大小(按页来计算),进程的每页都需要一帧。因此,如果进程需要 n 页,那么内存中至少应有 n 个帧。如果有,那么就可分配给新进程。进程的第一页装入一个已分配的帧,帧码放入进程的页表中。下一页分配给另一帧,其帧码也放入进程的页表中,等等(图 4 )。
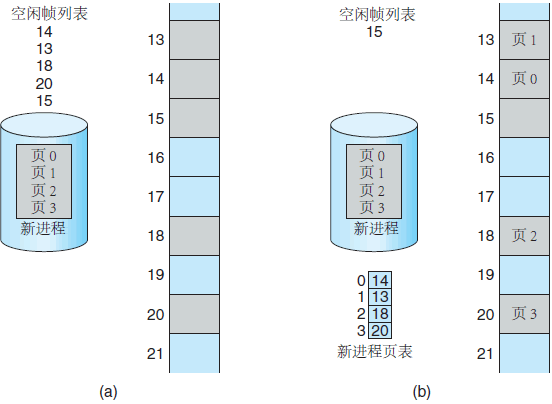
图 4 空闲帧
需要注意的是,程序员视图的内存和实际的物理内存看似清楚地分离。程序员将内存作为一整块来处理,而且它只包含这一个程序。事实上,一个用户程序与其他程序一起分散在物理内存上。程序员视图的内存和实际的物理内存的不同是通过地址转换硬件来协调的。
逻辑地址转变成物理地址。这种映射程序员是不知道的,它是由操作系统控制的。注意,根据定义,用户进程不能访问不属于它的内存。它无法访问它的页表规定之外的内存,页表只包括进程拥有的那些页。
由于操作系统管理物理内存,它应知道物理内存的分配细节:哪些帧已分配,哪些帧空着,总共有多少帧,等等。这些信息通常保存在称为帧表的数据结构中。在帧表中,每个条目对应着一个帧,以表示该帧是空闲还是已占用;如果占用,是被哪个(或哪些)进程的哪个页所占用。
另外,操作系统应意识到,用户进程是在用户空间内执行,所有逻辑地址需要映射到物理地址。如果用户执行一个系统调用(例如,要进行I/O),并提供地址作为参数(例如,一个缓冲),那么这个地址应映射,以形成正确的物理地址。
操作系统为每个进程维护一个页表的副本,就如同它需要维护指令计数器和寄存器的内容一样。每当操作系统自己将逻辑地址映射成物理地址时,这个副本可用作转换。当一个进程可分配到 CPU 时,CPU 分派器也根据该副本来定义硬件页表。因此,分页增加了上下文切换的时间。
页表的硬件实现有多种方法,最为简单的一种方法是将页表作为一组专用的寄存器来实现。由于每次访问内存都要经过分页映射,因此效率是一个重要的考虑因素,这些寄存器应用高速逻辑电路来构造,以高效地进行分页地址的转换。CPU 分派器在加载其他寄存器时,也需要加载这些寄存器。
当然,加载或修改页表寄存器的指令是特权的,因此只有操作系统才可以修改内存映射表。具有这种结构的一个例子是 DEC PDP-11。它的地址有 16 位,而页面大小为 8KB。因此页表有 8 个条目,可放在快速寄存器中。
如果页表比较小(例如 256 个条目),那么页表使用寄存器还是令人满意的。但是,大多数现代计算机都允许页表非常大(例如 100 万个条目)。对于这些机器,采用快速寄存器来实现页表就不可行了。因而需要将页表放在内存中,并将页表基地址寄存器(PTBR)指向页表。改变页表只需要改变这一寄存器就可以,这也大大降低了上下文切换的时间。
采用这种方法的问题是访问用户内存位置的所需时间。如果需要访问位置i,那么应首先利用PTBR的值,再加上i的页码作为偏移,来查找页表。这一任务需要内存访问。根据所得的帧码,再加上页偏移,就得到了真实物理地址。接着就可以访问内存内的所需位置。
采用这种方案,访问一个字节需要两次内存访问(一次用于页表条目,一次用于字节),内存访问的速度就减半。在大多数情况下,这种延迟是无法忍受的,我们还不如采用交换机制!
这个问题的标准解决方案是采用专用的、小的、查找快速的高速硬件缓冲,它称为转换表缓冲区(TLB)。TLB 是关联的髙速内存。TLB 条目由两部分组成:键(标签)和值。当关联内存根据给定值查找时,它会同时与所有的键进行比较。如果找到条目,那么就得到相应值的字段,搜索速度很快。
现代的 TLB 查找硬件是指令流水线的一部分,基本上不添加任何性能负担。为了能够在单步的流水线中执行搜索,TLB 不应大,通常它的大小在 32〜1024 之间。有些 CPU 采用分开的指令和数据地址的 TLB。这可以将 TLB 条目的数量扩大一倍,因为查找可以在不同的流水线步骤中进行。
通过这个演变,我们可以看到 CPU 技术的发展趋势:系统从没有 TLB 发展到具有多层的 TLB,与具有多层的高速缓存一样。
TLB 与页表一起使用的方法如下,TLB 只包含少数的页表条目。当 CPU 产生一个逻辑地址后,它的页码就发送到 TLB。如果找到这个页码,它的帧码也就立即可用,可用于访问内存。如上面所提到的,这些步骤可作为 CPU 的流水线的一部分来执行;与没有实现分页的系统相比,这并没有减低性能。
如果页码不在 TLB 中(称为TLB未命中),那么就需访问页表。取决于 CPU,这可能由硬件自动处理或通过操作系统的中断来处理。当得到帧码后,就可以用它来访问内存(见图 5)。另外,将页码和帧码添加到 TLB,这样下次再用时就可很快查找到。
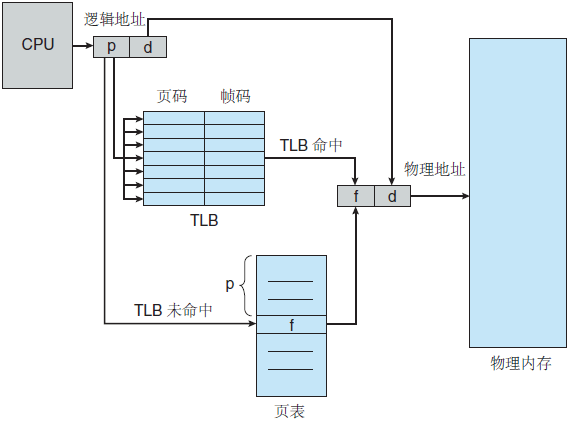
图 5 带 TLB 的分页硬件
如果 TLB 内的条目已满,那么会选择一个来替换。替换策略有很多,从最近最少使用替换(LRU),到轮转替换,到随机替换等。有的 CPU 允许操作系统参与 LRU 条目的替换,其他的自己负责替换。另外,有的 TLB 允许有些条目固定下来,也就是说,它们不会从 TLB 中被替换。通常,重要内核代码的条目是固定下来的。
有的 TLB 在每个 TLB 条目中还保存地址空间标识符(ASID)。ASID 唯一标识每个进程,并为进程提供地址空间的保护。当 TLB 试图解析虚拟页码时,它确保当前运行进程的 ASID 与虚拟页相关的 ASID 相匹配。如果不匹配,那么就作为 TLB 未命中。
除了提供地址空间保护外,ASID 也允许 TLB 同时包括多个不同进程的条目。如果 TLB 不支持单独的 ASID,每次选择一个页表时(例如,上下文切换时),TLB 就应被刷新(或删除),以确保下一个进程不会使用错误的地址转换。否则,TLB 内可能有旧的条目,它们包含有效的页码地址,但有从上一个进程遗留下来的不正确或无效的物理地址。
在 TLB 中查找到感兴趣页码的次数的百分比称为命中率。80% 的命中率意味着,有 80% 的时间可以在 TLB 中找到所需的页码。如果需要 100ns 来访问内存,那么当页码在 TLB 中时,访问映射内存需要 100ns。如果不能在 TLB 中找到,那么应先访问位于内存中的页表和帧码(100ns),并进而访问内存中的所需字节(100ns),这总共要花费 200ns。
为了求得有效内存访问时间,需要根据概率来进行加权:
对于 99% 的命中率,这是更现实的,我们有:
如前所述,现代 CPU 可能提供多级 TLB。因此,现代 CPU 的访问时间的计算,比上面的例子更为复杂。例如,Intel Core i7 CPU 有一个 128 指令条目的 L1 TLB 和 64 数据条目的 L1 TLB。当 L1 未命中时,CPU 花费 6 个周期来检查 L2 的 TLB 的 512 条目。L2 的未命中意味着,CPU 需要通过内存的页表条件来查找相关的帧地址,这可能需要数百个周期,或者通过中断操作系统以完成它的工作。
这种系统的分页开销的完整性能分析,需要关于每个 TLB 层次的命中率信息。然而,从这可以看到一条通用规律,硬件功能对内存性能有着显著的影响,而操作系统的改进(如分页)能导致硬件的改进并反过来受其影响。
TLB 是一个硬件功能,因此操作系统及其设计师似乎不必关心。但是设计师需要了解TLB的功能和特性,它们因硬件平台的不同而不同。为了优化运行,给定平台的操作系统设计应根据平台的 TLB 设计来实现分页。同样,TLB 设计的改变(例如,在多代 Intel CPU 之间)可能需要调整操作系统的分页实现。
用一个位可以定义一个页是可读可写或只可读。每次内存引用都要通过页表,来查找正确的帧码;在计算物理地址的同时,可以通过检查保护位来验证有没有对只可读页进行写操作。对只读页进行写操作会向操作系统产生硬件陷阱或内存保护冲突。
我们可轻松扩展这种方法,以提供更好的保护级别。我们可以创建硬件来提供只读、读写或只执行保护;或者,通过为每种类型的访问提供单独的保护位,我们可以允许这些访问的任何组合。非法访问会陷入操作系统。
还有一个位通常与页表中的每一条目相关联:有效-无效位:
通过使用有效-无效位,非法地址会被捕捉到。操作系统通过对该位的设置,可以允许或不允许对某页的访问。
例如,对于 14 位地址空间(0〜16383)的系统,假设有一个程序,它的有效地址空间为 0〜10468。如果页的大小为 2KB,那么页表如图 6 所示。
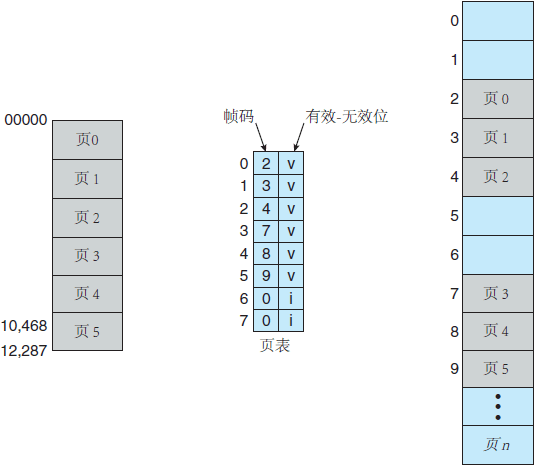
图 6 页表的有效位(v)或无效位(i)
页 0、1、2、3、4 和 5 的地址可以通过页表正常映射。然而,如果试图产生页表 6 或 7 内的地址时,则会发现有效-无效位为无效,这样操作系统就会捕捉到这一非法操作(无效页引用)。
注意,这种方法也产生了一个问题。由于程序的地址只到 10468,所以任何超过该地址的引用都是非法的。不过,由于对页5的访问是有效的,因此到 12287 为止的地址都是有效的。只有 12288〜16383 的地址才是无效的。这个问题是由于页大小为 2KB 的原因,也反映了分页的内部碎片。
一个进程很少会使用它的所有地址空间。事实上,许多进程只用到地址空间的小部分。对这些情况,如果为地址范围内的所有页都在页表中建立一个条目,这将是非常浪费的。表中的大多数并不会被使用,却占用可用的地址空间。有的系统提供硬件,如页表长度寄存器来表示页表的大小,该寄存器的值可用于检查每个逻辑地址以验证其是否位于进程的有效范围内。如果检测无法通过,则会被操作系统捕捉到。
假设一个支持 40 个用户的系统,每个都执行一个文本编辑器。如果该文本编辑器包括 150KB 的代码及 50KB 的数据空间,则需要 8000KB 来支持这 40 个用户。如果代码是可重入代码或纯代码,则可以共享,如图 7 所示。这里有 3 个进程,它们共享 3 页的编辑器,这里每页大小为 50KB,每个进程都有它自己的数据页。
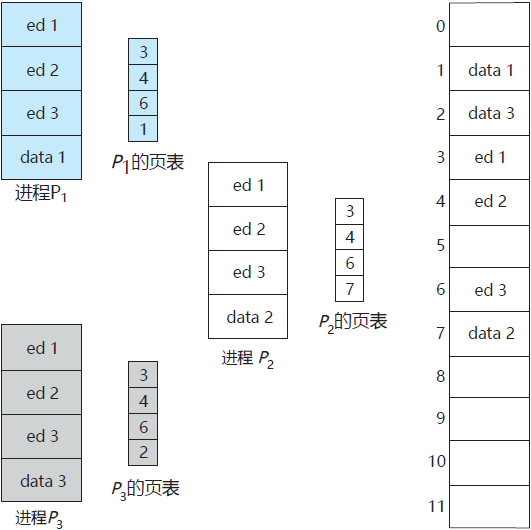
图 7 分页环境的代码共享
可重入代码是不能自我修改的代码:它在执行期间不会改变。因此,两个或更多个进程可以同时执行相同代码。每个进程都有它自己的寄存器副本和数据存储,以便保存进程执行的数据。当然,两个不同进程的数据不同。
在物理内存中,只需保存一个编辑器的副本。每个用户的页表映射到编辑器的同一物理副本,但是数据页映射到不同的帧。因此,为支持 40 个用户,只需一个编辑器副本(150KB),再加上 40 个用户数据空间 50KB,总的需求空间为 2150KB 而非 8000KB,这个节省还是很大的。
其他大量使用的程序也可以共享,如编译器、窗口系统、运行时库、数据库系统等。为了共享,代码应可重入。共享代码的只读属性不应由代码的正确性来保证;而应由操作系统来强制实现。
系统内进程之间的内存共享,类似于通过线程共享同一任务的地址空间。此外,回想一下,我们将共享内存用于进程间的通信,有的操作系统通过共享页来实现共享内存。
不仅如此,分页还避免了将不同大小的内存块匹配到交换空间的问题,在分页引入之前采用的内存管理方案都有这个问题。由于比早期方法更加优越,各种形式的分页为大多数操作系统采用,包括大型机的和智能手机的操作系统。实现分页需要操作系统和计算机硬件的协作。
基本方法
实现分页的基本方法涉及将物理内存分为固定大小的块,称为帧或页帧,而将逻辑内存也分为同样大小的块,称为页或页面。当需要执行一个进程时,它的页从文件系统或备份存储等处,加载到内存的可用帧。备份存储划分为固定大小的块,它与单个内存帧或与多个内存帧(簇)的大小一样。
这个相当简单的方法功能强且变化多。例如,逻辑地址空间现在完全独立于物理地址空间,因此,一个进程可以有一个 64 位的逻辑地址空间,而系统的物理内存小于 264 字节。
图 1 分页的硬件支持
图 2 逻辑内存和物理内存的分页模型
页大小(与帧大小一样)是由硬件来决定的。页的大小为 2 的幂;根据计算机体系结构的不同,页大小可从 512 字节到 1GB 不等。将页的大小选为 2 的幂可以方便地将逻辑地址转换为页码和页偏移。如果逻辑地址空间为 2m,且页大小为 2n 字节,那么逻辑地址的高 m-n 位表示页码,而低 n 位表示页偏移。这样,逻辑地址就如下图所示:
其中 p 作为页表的索引,而 d 作为页的偏移。
图 3 使用 4 字节的页对 32 字节的内存进行分页的例子
例如,假设如图 3 所示的内存。这里,逻辑的地址的 n 为 2,m 为 4。采用大小为 4 字节而物理内存为 32 字节(8 页),下面说明程序员的内存视图如何映射到物理内存。
逻辑地址 0 的页码为 0,页偏移为 0。根据页表,可以查到页码 0 对应帧 5,因此逻辑地址 0 映射到物理地址 20((5X4) + 0)。逻辑地址 3(页码为 0,页偏移为 3)映射到物理地址 23((5X4)+ 3)。逻辑地址 4 的页码为 1,页偏移为 0,根据页表,页码 1 对应为帧 6。因此,逻辑地址 4 映射到物理地址 24((6X4) + 0)。逻辑地址 13 映射到物理地址 9。
读者可能注意到,分页本身是一种动态的重定位。每个逻辑地址由分页硬件绑定为某个物理地址。采用分页类似于采用一组基址(重定位)寄存器,每个基址对应着一个内存帧。
采用分页方案不会产生外部碎片:每个空闲帧都可以分配给需要它的进程。不过,分页有内部碎片。注意,分配是以帧为单位进行的。如果进程所要求的内存并不是页的整数倍,那么最后一个帧就可能用不完。
例如,如果页的大小为 2048 字节,一个大小为 72 776 字节的进程需要 35 个页和 1086 字节。该进程会得到 36 个帧,因此有 2048-1086 = 962 字节的内部碎片。在最坏情况下,一个需要 n 页再加 1 字节的进程,需要分配 n + 1 个帧,这样几乎产生整个帧的内部碎片。
如果进程大小与页大小无关,那么每个进程的内部碎片的均值为半页。从这个角度来看,小的页面大小是可取的。不过,由于页表内的每项也有一定的开销,该开销随着页的增大而降低。再者,磁盘 I/O 操作随着传输量的增大也会更为有效。
一般来说,随着时间的推移,页的大小也随着进程、数据和内存的不断增大而增大。现在,页大小通常为 4KB〜8KB,有的系统可能支持更大的页。有的 CPU 和内核可能支持多种页大小。例如,Solaris 根据按页所存储的数据,可使用 8KB 或 4MB 的大小的页。研究人员正在研究,以便支持快速可变的页大小。
通常,对于 32 位的 CPU,每个页表条目是 4 字节长的,但是这个大小也可能改变。一个 32 位的条目可以指向 232 个物理帧中的任一个。如果帧为 4KB(212),那么具有 4 字节条目的系统可以访问 244字节大小(或 16TB)的物理内存。
这里我们应该注意到,分页内存系统的物理内存的大小不同于进程的最大逻辑大小。当进一步探索分页时,我们将引入其他的信息,这个信息应保存在页表条目中。该信息也减少了可用于帧地址的位数。因此,一个具有 32 位页表条目的系统可访问的物理内存可能小于最大值。32 位 CPU 采用 32 位地址,意味着,一个进程的空间只能为 232 字节(4GB)。因此,分页允许我们使用的物理内存大于 CPU 地址指针可访问的空间。
当系统进程需要执行时,它将检查该进程的大小(按页来计算),进程的每页都需要一帧。因此,如果进程需要 n 页,那么内存中至少应有 n 个帧。如果有,那么就可分配给新进程。进程的第一页装入一个已分配的帧,帧码放入进程的页表中。下一页分配给另一帧,其帧码也放入进程的页表中,等等(图 4 )。
图 4 空闲帧
需要注意的是,程序员视图的内存和实际的物理内存看似清楚地分离。程序员将内存作为一整块来处理,而且它只包含这一个程序。事实上,一个用户程序与其他程序一起分散在物理内存上。程序员视图的内存和实际的物理内存的不同是通过地址转换硬件来协调的。
逻辑地址转变成物理地址。这种映射程序员是不知道的,它是由操作系统控制的。注意,根据定义,用户进程不能访问不属于它的内存。它无法访问它的页表规定之外的内存,页表只包括进程拥有的那些页。
由于操作系统管理物理内存,它应知道物理内存的分配细节:哪些帧已分配,哪些帧空着,总共有多少帧,等等。这些信息通常保存在称为帧表的数据结构中。在帧表中,每个条目对应着一个帧,以表示该帧是空闲还是已占用;如果占用,是被哪个(或哪些)进程的哪个页所占用。
另外,操作系统应意识到,用户进程是在用户空间内执行,所有逻辑地址需要映射到物理地址。如果用户执行一个系统调用(例如,要进行I/O),并提供地址作为参数(例如,一个缓冲),那么这个地址应映射,以形成正确的物理地址。
操作系统为每个进程维护一个页表的副本,就如同它需要维护指令计数器和寄存器的内容一样。每当操作系统自己将逻辑地址映射成物理地址时,这个副本可用作转换。当一个进程可分配到 CPU 时,CPU 分派器也根据该副本来定义硬件页表。因此,分页增加了上下文切换的时间。
硬件支持
每个操作系统都有自己的保存页表的方法。有的为每个进程分配一个页表。页表的指针,与其他寄存器的值(如指令计数器),一起存入进程控制块。当分派器需要启动一个进程时,它应首先加载用户寄存器,并根据保存的用户页表来定义正确的硬件页表值。其他操作系统提供一个或多个页表,以便减少进程的上下文切换的开销。页表的硬件实现有多种方法,最为简单的一种方法是将页表作为一组专用的寄存器来实现。由于每次访问内存都要经过分页映射,因此效率是一个重要的考虑因素,这些寄存器应用高速逻辑电路来构造,以高效地进行分页地址的转换。CPU 分派器在加载其他寄存器时,也需要加载这些寄存器。
当然,加载或修改页表寄存器的指令是特权的,因此只有操作系统才可以修改内存映射表。具有这种结构的一个例子是 DEC PDP-11。它的地址有 16 位,而页面大小为 8KB。因此页表有 8 个条目,可放在快速寄存器中。
如果页表比较小(例如 256 个条目),那么页表使用寄存器还是令人满意的。但是,大多数现代计算机都允许页表非常大(例如 100 万个条目)。对于这些机器,采用快速寄存器来实现页表就不可行了。因而需要将页表放在内存中,并将页表基地址寄存器(PTBR)指向页表。改变页表只需要改变这一寄存器就可以,这也大大降低了上下文切换的时间。
采用这种方法的问题是访问用户内存位置的所需时间。如果需要访问位置i,那么应首先利用PTBR的值,再加上i的页码作为偏移,来查找页表。这一任务需要内存访问。根据所得的帧码,再加上页偏移,就得到了真实物理地址。接着就可以访问内存内的所需位置。
采用这种方案,访问一个字节需要两次内存访问(一次用于页表条目,一次用于字节),内存访问的速度就减半。在大多数情况下,这种延迟是无法忍受的,我们还不如采用交换机制!
这个问题的标准解决方案是采用专用的、小的、查找快速的高速硬件缓冲,它称为转换表缓冲区(TLB)。TLB 是关联的髙速内存。TLB 条目由两部分组成:键(标签)和值。当关联内存根据给定值查找时,它会同时与所有的键进行比较。如果找到条目,那么就得到相应值的字段,搜索速度很快。
现代的 TLB 查找硬件是指令流水线的一部分,基本上不添加任何性能负担。为了能够在单步的流水线中执行搜索,TLB 不应大,通常它的大小在 32〜1024 之间。有些 CPU 采用分开的指令和数据地址的 TLB。这可以将 TLB 条目的数量扩大一倍,因为查找可以在不同的流水线步骤中进行。
通过这个演变,我们可以看到 CPU 技术的发展趋势:系统从没有 TLB 发展到具有多层的 TLB,与具有多层的高速缓存一样。
TLB 与页表一起使用的方法如下,TLB 只包含少数的页表条目。当 CPU 产生一个逻辑地址后,它的页码就发送到 TLB。如果找到这个页码,它的帧码也就立即可用,可用于访问内存。如上面所提到的,这些步骤可作为 CPU 的流水线的一部分来执行;与没有实现分页的系统相比,这并没有减低性能。
如果页码不在 TLB 中(称为TLB未命中),那么就需访问页表。取决于 CPU,这可能由硬件自动处理或通过操作系统的中断来处理。当得到帧码后,就可以用它来访问内存(见图 5)。另外,将页码和帧码添加到 TLB,这样下次再用时就可很快查找到。
图 5 带 TLB 的分页硬件
如果 TLB 内的条目已满,那么会选择一个来替换。替换策略有很多,从最近最少使用替换(LRU),到轮转替换,到随机替换等。有的 CPU 允许操作系统参与 LRU 条目的替换,其他的自己负责替换。另外,有的 TLB 允许有些条目固定下来,也就是说,它们不会从 TLB 中被替换。通常,重要内核代码的条目是固定下来的。
有的 TLB 在每个 TLB 条目中还保存地址空间标识符(ASID)。ASID 唯一标识每个进程,并为进程提供地址空间的保护。当 TLB 试图解析虚拟页码时,它确保当前运行进程的 ASID 与虚拟页相关的 ASID 相匹配。如果不匹配,那么就作为 TLB 未命中。
除了提供地址空间保护外,ASID 也允许 TLB 同时包括多个不同进程的条目。如果 TLB 不支持单独的 ASID,每次选择一个页表时(例如,上下文切换时),TLB 就应被刷新(或删除),以确保下一个进程不会使用错误的地址转换。否则,TLB 内可能有旧的条目,它们包含有效的页码地址,但有从上一个进程遗留下来的不正确或无效的物理地址。
在 TLB 中查找到感兴趣页码的次数的百分比称为命中率。80% 的命中率意味着,有 80% 的时间可以在 TLB 中找到所需的页码。如果需要 100ns 来访问内存,那么当页码在 TLB 中时,访问映射内存需要 100ns。如果不能在 TLB 中找到,那么应先访问位于内存中的页表和帧码(100ns),并进而访问内存中的所需字节(100ns),这总共要花费 200ns。
为了求得有效内存访问时间,需要根据概率来进行加权:
有效访问时间=0.80X100 + 0.20X200= 120ns
对于本例,平均内存访问时间多了 20% (从100〜120ns)。对于 99% 的命中率,这是更现实的,我们有:
有效访问时间=0.99X100 + 0.01X200= 101ns
这种命中率的提高只多了 1% 的访问时间。如前所述,现代 CPU 可能提供多级 TLB。因此,现代 CPU 的访问时间的计算,比上面的例子更为复杂。例如,Intel Core i7 CPU 有一个 128 指令条目的 L1 TLB 和 64 数据条目的 L1 TLB。当 L1 未命中时,CPU 花费 6 个周期来检查 L2 的 TLB 的 512 条目。L2 的未命中意味着,CPU 需要通过内存的页表条件来查找相关的帧地址,这可能需要数百个周期,或者通过中断操作系统以完成它的工作。
这种系统的分页开销的完整性能分析,需要关于每个 TLB 层次的命中率信息。然而,从这可以看到一条通用规律,硬件功能对内存性能有着显著的影响,而操作系统的改进(如分页)能导致硬件的改进并反过来受其影响。
TLB 是一个硬件功能,因此操作系统及其设计师似乎不必关心。但是设计师需要了解TLB的功能和特性,它们因硬件平台的不同而不同。为了优化运行,给定平台的操作系统设计应根据平台的 TLB 设计来实现分页。同样,TLB 设计的改变(例如,在多代 Intel CPU 之间)可能需要调整操作系统的分页实现。
保护
分页环境下的内存保护是通过与每个帧关联的保护位来实现的。通常,这些位保存在页表中。用一个位可以定义一个页是可读可写或只可读。每次内存引用都要通过页表,来查找正确的帧码;在计算物理地址的同时,可以通过检查保护位来验证有没有对只可读页进行写操作。对只读页进行写操作会向操作系统产生硬件陷阱或内存保护冲突。
我们可轻松扩展这种方法,以提供更好的保护级别。我们可以创建硬件来提供只读、读写或只执行保护;或者,通过为每种类型的访问提供单独的保护位,我们可以允许这些访问的任何组合。非法访问会陷入操作系统。
还有一个位通常与页表中的每一条目相关联:有效-无效位:
- 当该位为有效时,该值表示相关的页在进程的逻辑地址空间内,因此是合法(或有效)的页;
- 当该位为无效时,该值表示相关的页不在进程的逻辑地址空间内。
通过使用有效-无效位,非法地址会被捕捉到。操作系统通过对该位的设置,可以允许或不允许对某页的访问。
例如,对于 14 位地址空间(0〜16383)的系统,假设有一个程序,它的有效地址空间为 0〜10468。如果页的大小为 2KB,那么页表如图 6 所示。
图 6 页表的有效位(v)或无效位(i)
页 0、1、2、3、4 和 5 的地址可以通过页表正常映射。然而,如果试图产生页表 6 或 7 内的地址时,则会发现有效-无效位为无效,这样操作系统就会捕捉到这一非法操作(无效页引用)。
注意,这种方法也产生了一个问题。由于程序的地址只到 10468,所以任何超过该地址的引用都是非法的。不过,由于对页5的访问是有效的,因此到 12287 为止的地址都是有效的。只有 12288〜16383 的地址才是无效的。这个问题是由于页大小为 2KB 的原因,也反映了分页的内部碎片。
一个进程很少会使用它的所有地址空间。事实上,许多进程只用到地址空间的小部分。对这些情况,如果为地址范围内的所有页都在页表中建立一个条目,这将是非常浪费的。表中的大多数并不会被使用,却占用可用的地址空间。有的系统提供硬件,如页表长度寄存器来表示页表的大小,该寄存器的值可用于检查每个逻辑地址以验证其是否位于进程的有效范围内。如果检测无法通过,则会被操作系统捕捉到。
共享页
分页的优点之一是可以共享公共代码。对于分时环境,这种考虑特别重要。假设一个支持 40 个用户的系统,每个都执行一个文本编辑器。如果该文本编辑器包括 150KB 的代码及 50KB 的数据空间,则需要 8000KB 来支持这 40 个用户。如果代码是可重入代码或纯代码,则可以共享,如图 7 所示。这里有 3 个进程,它们共享 3 页的编辑器,这里每页大小为 50KB,每个进程都有它自己的数据页。
图 7 分页环境的代码共享
可重入代码是不能自我修改的代码:它在执行期间不会改变。因此,两个或更多个进程可以同时执行相同代码。每个进程都有它自己的寄存器副本和数据存储,以便保存进程执行的数据。当然,两个不同进程的数据不同。
在物理内存中,只需保存一个编辑器的副本。每个用户的页表映射到编辑器的同一物理副本,但是数据页映射到不同的帧。因此,为支持 40 个用户,只需一个编辑器副本(150KB),再加上 40 个用户数据空间 50KB,总的需求空间为 2150KB 而非 8000KB,这个节省还是很大的。
其他大量使用的程序也可以共享,如编译器、窗口系统、运行时库、数据库系统等。为了共享,代码应可重入。共享代码的只读属性不应由代码的正确性来保证;而应由操作系统来强制实现。
系统内进程之间的内存共享,类似于通过线程共享同一任务的地址空间。此外,回想一下,我们将共享内存用于进程间的通信,有的操作系统通过共享页来实现共享内存。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算