内存分段机制详解
通过学习内存分配的方式我们知道,用户的内存视图与实际的物理内存不一样。这同样适用于程序员的内存视图。
事实上,对操作系统和程序员来说,按物理性质来处理内存是不方便的。如果硬件可以提供内存机制,以便将程序员的内存视图映射到实际的物理内存,系统将有更多的自由来管理内存,而程序员将有一个更自然的编程环境。分段提供了这种机制。
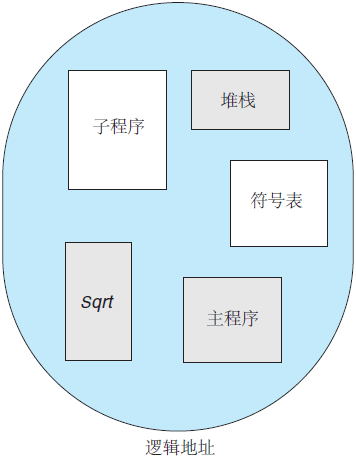
图 1 程序员眼中的程序
当编写程序时,程序员认为它是由主程序加上一组方法、过程或函数所构成的。它还可以包括各种数据结构,例如对象、数组、堆栈、变量等。每个模块或数据元素通过名称来引用。程序员会说“堆栈”、“数学库”和“主程序”等,而并不关心这些元素所在内存的位置,及他不关心堆栈是放在函数 Sqrt() 之前还是之后。
这些段的长度是不同的,其长度是由这些段在程序中的目的决定的。段内的元素是通过它们距段首的偏移来指定程序的第一条语句、在堆栈里的第 7 个栈帧、函数 Sqrt() 的第 5 条指令等。
分段就是支持这种用户视图的内存管理方案。逻辑地址空间是由一组段构成。每个段都有名称和长度。地址指定了段名称和段内偏移。因此用户通过两个量来指定地址:段名称和段偏移。
为了实现简单起见,段是编号的,通过段号而不是段名称来引用。因此,逻辑地址由有序对组成:
一个 C 编译器可能会创建如下段:,
在编译时链接的库可能分配不同的段。加载程序会装入所有这些段,并为它们分配段号。
段表的每个条目都有段基地址和段界限。段基地址包含该段在内存中的开始物理地址,而段界限指定该段的长度。
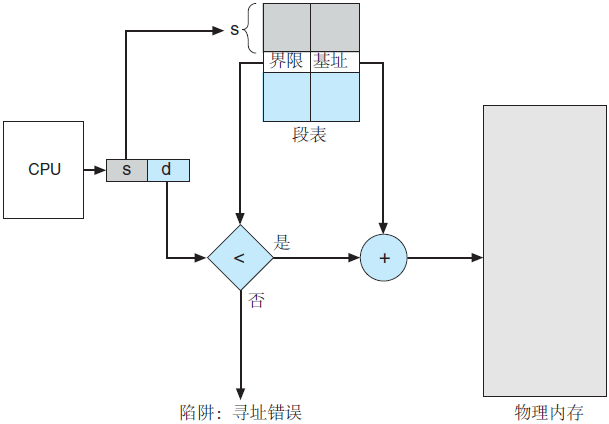
图 2 分段硬件
段表的使用如图 2 所示。每个逻辑地址由两部分组成:段号 s 和段偏移 d。段号用作段表的索引,逻辑地址的偏移 d 应位于 0 和段界限之间。如果不是这样,那么会陷入操作系统中(逻辑地址试图访问段的外面)。如果偏移d合法,那么就与基地址相加而得到所需字节的物理内存地址。因此,段表实际上是基址寄存器值和界限寄存器值的对的数组。
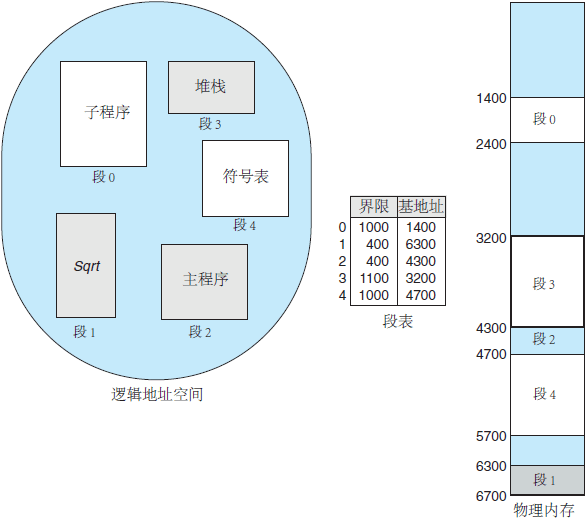
图 3 分段的例子
例如,假设如图 3 所示的情况。有 5 个段,按 0〜4 来编号。各段按如图所示来存储。每个段都在段表中有一个条目,它包括段在物理内存内的开始地址(基地址)和该段的长度(界限)。
例如,段 2 为 400 字节长,开始于位置 4300。因此,对段 2 字节 53 的引用映射成位置 4300 + 53 = 4353。对段 3 字节 852 的引用映射成位置 3200 (段 3 基地址)+ 852 = 4052。对段 0 字节 1222 的引用会陷入操作系统,这是由于该段仅为 1000 字节长。
事实上,对操作系统和程序员来说,按物理性质来处理内存是不方便的。如果硬件可以提供内存机制,以便将程序员的内存视图映射到实际的物理内存,系统将有更多的自由来管理内存,而程序员将有一个更自然的编程环境。分段提供了这种机制。
分段的基本方法
程序员是否认为内存是一个字节的线性数组,有的包含指令而其他的包含数据?大多数程序员会说“不”。相反,程序员通常愿意将内存看作一组不同长度的段,这些段之间并没有一定的顺序(图 1)。图 1 程序员眼中的程序
当编写程序时,程序员认为它是由主程序加上一组方法、过程或函数所构成的。它还可以包括各种数据结构,例如对象、数组、堆栈、变量等。每个模块或数据元素通过名称来引用。程序员会说“堆栈”、“数学库”和“主程序”等,而并不关心这些元素所在内存的位置,及他不关心堆栈是放在函数 Sqrt() 之前还是之后。
这些段的长度是不同的,其长度是由这些段在程序中的目的决定的。段内的元素是通过它们距段首的偏移来指定程序的第一条语句、在堆栈里的第 7 个栈帧、函数 Sqrt() 的第 5 条指令等。
分段就是支持这种用户视图的内存管理方案。逻辑地址空间是由一组段构成。每个段都有名称和长度。地址指定了段名称和段内偏移。因此用户通过两个量来指定地址:段名称和段偏移。
为了实现简单起见,段是编号的,通过段号而不是段名称来引用。因此,逻辑地址由有序对组成:
<段号,偏移>
通常,在编译用户程序时,编译器会根据输入程序来自动构造段。一个 C 编译器可能会创建如下段:,
- 代码
- 全局变量
- 堆(内存从堆上分配)
- 每个线程使用的栈
- 标准的C库
在编译时链接的库可能分配不同的段。加载程序会装入所有这些段,并为它们分配段号。
分段硬件
虽然用户现在能够通过二维地址来引用程序内的对象,但是实际物理内存仍然是一维的字节序列。因此,我们应定义一个实现方式,以便映射用户定义的二维地址到一维物理地址。这个地址是通过段表来实现的。段表的每个条目都有段基地址和段界限。段基地址包含该段在内存中的开始物理地址,而段界限指定该段的长度。
图 2 分段硬件
段表的使用如图 2 所示。每个逻辑地址由两部分组成:段号 s 和段偏移 d。段号用作段表的索引,逻辑地址的偏移 d 应位于 0 和段界限之间。如果不是这样,那么会陷入操作系统中(逻辑地址试图访问段的外面)。如果偏移d合法,那么就与基地址相加而得到所需字节的物理内存地址。因此,段表实际上是基址寄存器值和界限寄存器值的对的数组。
图 3 分段的例子
例如,假设如图 3 所示的情况。有 5 个段,按 0〜4 来编号。各段按如图所示来存储。每个段都在段表中有一个条目,它包括段在物理内存内的开始地址(基地址)和该段的长度(界限)。
例如,段 2 为 400 字节长,开始于位置 4300。因此,对段 2 字节 53 的引用映射成位置 4300 + 53 = 4353。对段 3 字节 852 的引用映射成位置 3200 (段 3 基地址)+ 852 = 4052。对段 0 字节 1222 的引用会陷入操作系统,这是由于该段仅为 1000 字节长。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算