首页 > 汇编语言 > 汇编语言字符串和数组
汇编语言冒泡排序简述
冒泡排序从位置 0 和 1 开始,对比数组的两个数值。如果比较结果为逆序,就交换这两个数。下图展示了对一个整数数组进行一次遍历的过程。
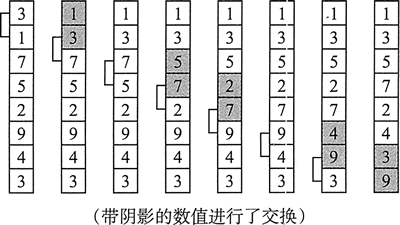
一次冒泡过程之后,数组仍没有按序排列,但此时最高索引位置上是最大数。外层循环则开始对该数组再一次遍历。经过 1 次遍历后,数组就会按序排列。
冒泡排序对小型数组效果很好,但对较大的数组而言,它的效率就十分低下。计算机科学家在衡量算法的相对效率时,常常使用一种被称为 “时间复杂度”(big-O)的概念来描述随着处理对象数量的增加,平均运行时间是如何增加的。
冒泡排序是 O (n²) 算法,这就意味着,它的平均运行时间随着数组元素 (n) 个数的平方增加。比如,假设 1000 个元素排序需要 0.1 秒。当元素个数增加 10 倍时,该数组排序所需要的时间就会增加 10² (100) 倍。
下表列出了不同数组大小需要的排序时间,假设 1000 个数组元素排序花费 0.1 秒:
对于一百万个整数来说,冒泡排序谈不上有效率,因为它完成任务的时间太长了!但是对于几百个整数,它的效率是足够的。
用类似于汇编语言的伪代码为冒泡排序编写的简化代码是有用的。代码用 N 表示数组大小,cx1 表示外循环计数器,cx2 表示内循环计数器:
根据伪代码能够很容易生成与之对应的汇编程序,并将它表示为带参数和局部变量的过程:
一次冒泡过程之后,数组仍没有按序排列,但此时最高索引位置上是最大数。外层循环则开始对该数组再一次遍历。经过 1 次遍历后,数组就会按序排列。
冒泡排序对小型数组效果很好,但对较大的数组而言,它的效率就十分低下。计算机科学家在衡量算法的相对效率时,常常使用一种被称为 “时间复杂度”(big-O)的概念来描述随着处理对象数量的增加,平均运行时间是如何增加的。
冒泡排序是 O (n²) 算法,这就意味着,它的平均运行时间随着数组元素 (n) 个数的平方增加。比如,假设 1000 个元素排序需要 0.1 秒。当元素个数增加 10 倍时,该数组排序所需要的时间就会增加 10² (100) 倍。
下表列出了不同数组大小需要的排序时间,假设 1000 个数组元素排序花费 0.1 秒:
| 数组大小 | 时间(秒) | 数组大小 | 时间(秒) |
|---|---|---|---|
| 1 000 | 0.1 | 100 000 | 1000 |
| 10 000 | 10.0 | 1 000 000 | 100 000 (27.78 小时) |
对于一百万个整数来说,冒泡排序谈不上有效率,因为它完成任务的时间太长了!但是对于几百个整数,它的效率是足够的。
用类似于汇编语言的伪代码为冒泡排序编写的简化代码是有用的。代码用 N 表示数组大小,cx1 表示外循环计数器,cx2 表示内循环计数器:
cx1 = N - 1
while( cxl > 0 )
{
esi = addr (array)
cx2 = cx1
while ( cx2 > 0 )
{
if(array[esi] > array[esi+4])
exchange(array[esi], array[esi+4])
add esi,4
dec cx2
}
dec cxl
}
如保存和恢复外循环计数器等的机械问题被刻意忽略了。注意内循环计数 (cx2) 是基于外循环计数 (cx1) 当前值的,每次遍历数组时它都依次递减。根据伪代码能够很容易生成与之对应的汇编程序,并将它表示为带参数和局部变量的过程:
;----------------------------------------
;BubbleSort
;使用冒泡算法,将一个 32 位有符号整数数组按升序进行排列。
;接收:数组指针,数组大小
;返回:无
;----------------------------------------
BubbleSort PROC USES eax ecx esi,
pArray:PTR DWORD, ;数组指针
Count: DWORD ;数组大小
mov ecx,Count
dec ecx ;计数值减1
L1: push ecx ;保存外循环计数值
mov esi,pArray ;指向第一个数值
L2: mov eax, [esi] ;取数组元素值
cmp [esi+4],eax ;比较两个数值
jg L3 ;如果[ESI]<=[ESI + 4],不交换
xchg eax, [esi+4] ;交换两数
mov [esi],eax
L3: add esi,4 ;两个指针都向前移动一个元素
loop L2 ;内循环
pop ecx ;恢复外循环计数值
loop L1 ;若计数值不等于0,则继续外循环
L4: ret
BubbleSort ENDP
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算